【データ同化入門】なぜ一部の実測で未観測データが分かる?

こんにちは(@t_kun_kamakiri)
CAE解析やインハウスコードを使っていると、次のような場面によく出会います。
- シミュレーションは空間全体の分布を出してくれるが、実測値とは少しズレる
- 実測値は信頼できるが、センサを置いた場所の値しかわからない
- 「シミュレーションと実測、結局どちらを信じればよいのか?」で悩む
この問題に対して、シミュレーションの分布情報と観測データの信頼性を、数式に基づいて融合する技術がデータ同化です。
この記事では、データ同化の最も基本的な考え方を、1次元の温度分布モデルを使って説明します。特に、データ同化の中心にあるカルマンゲインが「何を意味していて、どう導かれるのか」を丁寧に追います。
- データ同化が「シミュレーションと観測のいいとこ取り」と言われる理由
- システムモデルと観測モデルの意味
- 状態、真値、誤差をどう数式で表すか
- カルマンゲインの導出と、その物理的な意味
- なぜ1点の観測だけで、観測していない場所まで修正できるのか
1. シミュレーションと実測は、それぞれ違う弱点を持つ
ものづくりや気象予測、熱流体解析では、現象を知るために主に2つの方法を使います。
1つはシミュレーションです。支配方程式を解くことで、空間全体の温度・速度・圧力などの分布を得られます。
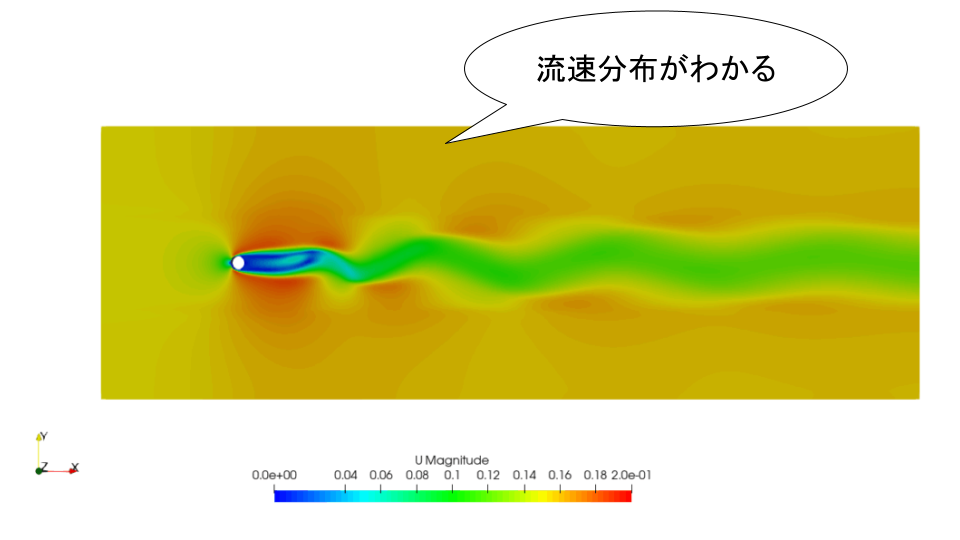
もう1つは実測です。温度センサや圧力センサを置けば、その場所の値を現実から直接得られます。
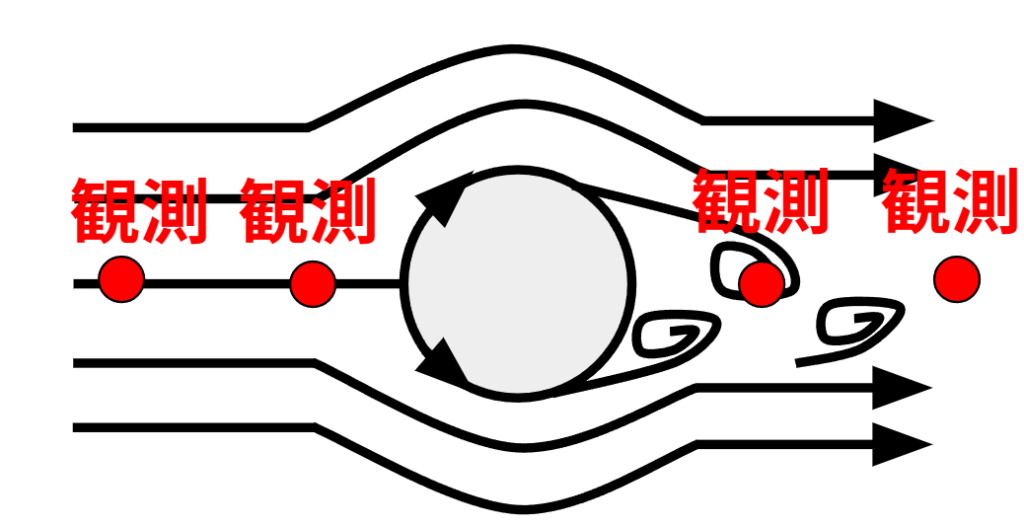
ただし、どちらも単独では完璧ではありません。
| 方法 | 強み | 弱み |
|---|---|---|
| シミュレーション | 空間全体の分布がわかる | 境界条件、初期条件、モデル化の誤差で実測とズレる |
| 実測 | 現実の値を直接反映している | センサを置いた場所しかわからない。測定ノイズもある |
データ同化は、この2つを対立させるのではなく、「どちらをどれだけ信じるか」を誤差の大きさに応じて決める方法です。
2. まず「真値」と「誤差」を分けて考える
データ同化を理解するうえで最初に大事なのは、シミュレーション値も観測値も、真値そのものではないと考えることです。
本当の状態を $\mathbf{x}^t$ と書きます。ここで上付きの $t$ は true、つまり真値を表します。
シミュレーションが出した予測値を $\mathbf{x}^f$ と書きます。上付きの $f$ は forecast、つまり予報値・予測値です。
このとき、予測値は真値に誤差が乗ったものとして表せます。
\mathbf{x}^f
=
\mathbf{x}^t
+
\boldsymbol{\varepsilon}^f
\end{align*}
ここで $\boldsymbol{\varepsilon}^f$ は予報誤差です。つまり、
\boldsymbol{\varepsilon}^f
=
\mathbf{x}^f
–
\mathbf{x}^t
\end{align*}
です。
同じように、観測値 $\mathbf{y}$ も真値そのものではありません。センサには測定ノイズがあるため、観測値は次のように書きます。
\mathbf{y}
=
\mathbf{H}\mathbf{x}^t
+
\boldsymbol{\varepsilon}^o
\end{align*}
ここで、$\boldsymbol{\varepsilon}^o$ は観測誤差です。$\mathbf{H}$ は観測演算子で、シミュレーションの全状態から「センサが見ている成分だけを取り出す」役割を持ちます。
この時点で、データ同化の考え方は次のように整理できます。
- シミュレーション値 $\mathbf{x}^f$ は、真値 $\mathbf{x}^t$ から予報誤差だけズレている
- 観測値 $\mathbf{y}$ は、真値をセンサで見た値 $\mathbf{H}\mathbf{x}^t$ から観測誤差だけズレている
- どちらにも誤差があるので、両方を統計的に混ぜて最良推定を作る
3. システムモデルと観測モデル
データ同化では、現象の時間発展と観測を分けて考えます。
システムモデル
システムモデルは、状態が時間とともにどう進むかを表す式です。時刻 $n-1$の状態から、時刻$n$ の状態を予測します。
\mathbf{x}_n^t
=
\mathbf{M}_{n-1}
\mathbf{x}_{n-1}^t
+
\boldsymbol{\eta}_{n-1}
\end{align*}
ここで、$\mathbf{M}_{n-1}$ は時間発展モデルです。熱伝導なら熱方程式、流体ならNavier-Stokes方程式を離散化したものに相当します。$\boldsymbol{\eta}_{n-1}$ はモデル誤差です。
もう少し具体的に、1次元の熱伝導方程式で考えてみます。温度を $T$、熱拡散率を $\kappa$ とすると、連続式は次のように書けます。
\frac{\partial T}{\partial t}
=
\kappa
\frac{\partial^2 T}{\partial x^2}
\end{align*}
これを空間格子と時間ステップで差分化します。格子点 $i$、時刻 $n$の温度を$T_i^n$ とし、陽解法で書くと、
T_i^n
=
T_i^{n-1}
+
r
\left(
T_{i-1}^{n-1}
–
2T_i^{n-1}
+
T_{i+1}^{n-1}
\right)
\end{align*}
です。ここで、
r
=
\frac{\kappa \Delta t}{\Delta x^2}
\end{align*}
です。
この $r$ は、1ステップの時間で、隣の格子点からどれくらい熱の影響を受けるかを表す係数です。
- $\kappa$が大きいほど、熱が伝わりやすいので$r$ は大きくなる
- $\Delta t$が大きいほど、長い時間だけ熱が伝わるので$r$ は大きくなる
- $\Delta x$が小さいほど、隣の格子点が近くなるので$r$ は大きくなる
つまり $r$ は、「熱の伝わりやすさ」と「時間刻み」と「格子の細かさ」をまとめた係数です。
差分式
T_i^n
=
T_i^{n-1}
+
r
\left(
T_{i-1}^{n-1}
–
2T_i^{n-1}
+
T_{i+1}^{n-1}
\right)
\end{align*}
を見ると、$r$ は左右の温度差による修正量に掛かっています。したがって、$r$ が大きいほど、1ステップで温度が大きく変わります。
なお、陽解法では $r$ を大きくしすぎると数値計算が不安定になります。1次元熱伝導の基本的な陽解法では、目安として
r
\leq
\frac{1}{2}
\end{align*}
を満たすように $\Delta t$ を選びます。
この式全体は、言葉で言えば「次の時刻の温度は、今の温度と、左右の格子から流れ込む熱で決まる」という意味です。
この差分式を全格子点についてまとめて書くと、次のような行列の形になります。
\begin{pmatrix}
T_1^n \\
T_2^n \\
T_3^n \\
\vdots \\
T_{N-2}^n
\end{pmatrix}
=
\begin{pmatrix}
1-2r & r & 0 & \cdots & 0 \\
r & 1-2r & r & \cdots & 0 \\
0 & r & 1-2r & \cdots & 0 \\
\vdots & \vdots & \vdots & \ddots & r \\
0 & 0 & 0 & r & 1-2r
\end{pmatrix}
\begin{pmatrix}
T_1^{n-1} \\
T_2^{n-1} \\
T_3^{n-1} \\
\vdots \\
T_{N-2}^{n-1}
\end{pmatrix}
\end{align*}
この真ん中の三重対角行列が、熱伝導方程式を差分化したときの $\mathbf{M}_{n-1}$です。つまり$\mathbf{M}_{n-1}$は、時刻$n-1$の温度分布を、時刻$n$ の温度分布へ変換する行列と捉えられます。
ただし、このように $\mathbf{M}_{n-1}$を普通の行列として書けるのは、基本的には線形モデルの場合です。熱拡散率$\kappa$ が一定で、境界条件も線形に扱えるなら、熱伝導方程式は線形なので行列で表せます。
一方、物性値が温度に依存する、放射熱伝達が入る、流体方程式の移流項のように状態同士の掛け算が入る、といった場合は非線形になります。その場合は、
\mathbf{x}_n
=
\mathcal{M}_{n-1}
\left(
\mathbf{x}_{n-1}
\right)
\end{align*}
のように、行列 $\mathbf{M}$ではなく非線形な写像$\mathcal{M}$として書く方が自然です。カルマンフィルタの基本形では線形モデルを仮定しますが、拡張カルマンフィルタやアンサンブルカルマンフィルタでは、この非線形モデルを扱えるように拡張していきます。
実際の計算では真値 $\mathbf{x}_{n-1}^t$ はわからないので、前回の推定値 $\mathbf{x}_{n-1}^a$ から予測値を作ります。
\mathbf{x}_n^f
=
\mathbf{M}_{n-1}
\mathbf{x}_{n-1}^a
\end{align*}
この $\mathbf{x}_n^f$ が、観測を取り込む前のシミュレーション予測です。
観測モデル
観測モデルは、状態 $\mathbf{x}_n^t$ が与えられたとき、センサが何を測るかを表します。
\mathbf{y}_n
=
\mathbf{H}_n
\mathbf{x}_n^t
+
\boldsymbol{\varepsilon}_n^o
\end{align*}
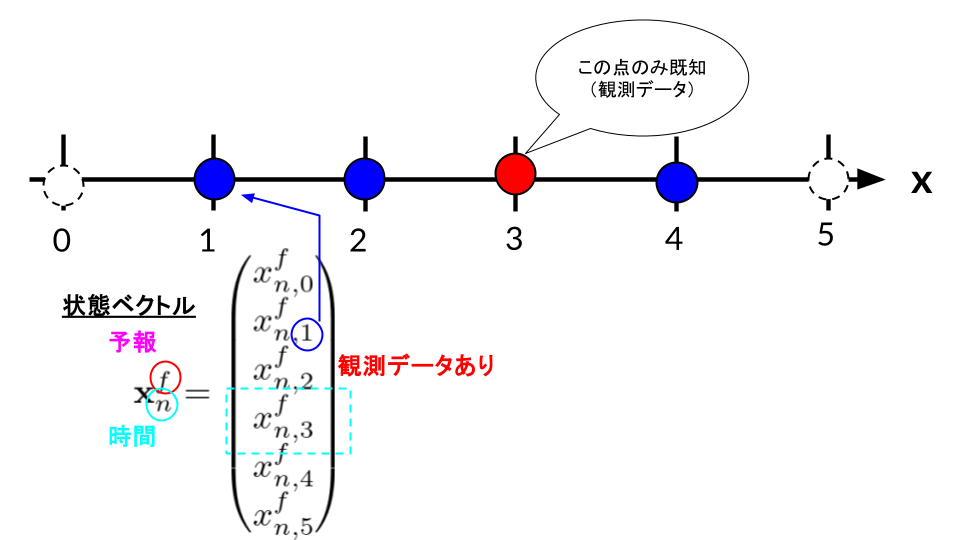
たとえば空間に6点の格子があり、位置3だけに温度センサがあるなら、状態ベクトルは次のように書けます。
\mathbf{x}_n
=
\begin{pmatrix}
x_{n,0} \\
x_{n,1} \\
x_{n,2} \\
x_{n,3} \\
x_{n,4} \\
x_{n,5}
\end{pmatrix}
\end{align*}
このうち位置3だけを取り出す観測行列は、
\mathbf{H}
=
\begin{pmatrix}
0 & 0 & 0 & 1 & 0 & 0
\end{pmatrix}
\end{align*}
です。したがって、観測予測値は
\mathbf{H}\mathbf{x}_n^f
=
x_{n,3}^f
\end{align*}
になります。
観測値 $y_{n,3}$とシミュレーションが予測したセンサ値$x_{n,3}^f$ の差は、
d_n
=
y_{n,3}
–
x_{n,3}^f
\end{align*}
です。この差を観測残差、またはinnovationと呼びます。データ同化は、この観測残差を使ってシミュレーション全体を修正します。
4. 予報誤差共分散行列は「間違い方の地図」
カルマンフィルタでは、シミュレーションの不確かさを予報誤差共分散行列で表します。
\mathbf{P}_n^f
=
E
\left[
\boldsymbol{\varepsilon}_n^f
{\boldsymbol{\varepsilon}_n^f}^{T}
\right]
\end{align*}
ここで $E[\cdot]$ は平均、つまり期待値です。
6点の1次元格子なら、$\mathbf{P}_n^f$は次のような$6 \times 6$ 行列になります。
\mathbf{P}_n^f
=
\begin{pmatrix}
\sigma_{00} & \sigma_{01} & \sigma_{02} & \sigma_{03} & \sigma_{04} & \sigma_{05} \\
\sigma_{10} & \sigma_{11} & \sigma_{12} & \sigma_{13} & \sigma_{14} & \sigma_{15} \\
\sigma_{20} & \sigma_{21} & \sigma_{22} & \sigma_{23} & \sigma_{24} & \sigma_{25} \\
\sigma_{30} & \sigma_{31} & \sigma_{32} & \sigma_{33} & \sigma_{34} & \sigma_{35} \\
\sigma_{40} & \sigma_{41} & \sigma_{42} & \sigma_{43} & \sigma_{44} & \sigma_{45} \\
\sigma_{50} & \sigma_{51} & \sigma_{52} & \sigma_{53} & \sigma_{54} & \sigma_{55}
\end{pmatrix}
\end{align*}
対角成分:その場所の自信のなさ
たとえば位置1の対角成分は、
\sigma_{11}
=
E
\left[
\left(
x_{n,1}^f
–
x_{n,1}^t
\right)^2
\right]
\end{align*}
です。これは位置1の予測が真値からどれくらい外れやすいか、つまり位置1におけるシミュレーションの自信のなさを表します。
非対角成分:2つの場所の間違い方の連動
位置1と位置3の共分散は、
\sigma_{13}
=
E
\left[
\left(
x_{n,1}^f
–
x_{n,1}^t
\right)
\left(
x_{n,3}^f
–
x_{n,3}^t
\right)
\right]
\end{align*}
です。これは、位置3の予測が高めに外れたとき、位置1も高めに外れやすいかどうかを表します。
熱伝導では隣り合う点が物理的につながっています。ある場所の境界条件を間違えると、その誤差は周囲に広がります。つまり、シミュレーションの誤差には空間的なクセがあります。そのクセを行列として持っているのが $\mathbf{P}_n^f$ です。
5. カルマンゲインは「観測残差をどこへ配るか」を決める
データ同化で求めたいのは、観測を取り込んだ後の推定値です。これを解析値と呼び、$\mathbf{x}_n^a$ と書きます。
カルマンフィルタの更新式は、次の形です。
\mathbf{x}_n^a
=
\mathbf{x}_n^f
+
\mathbf{K}_n
\left(
\mathbf{y}_n
–
\mathbf{H}_n
\mathbf{x}_n^f
\right)
\end{align*}
この式は、言葉にすると次の意味です。
\text{修正後の値}
=
\text{シミュレーション予測}
+
\text{カルマンゲイン}
\times
\text{観測残差}
\end{align*}
ここで重要なのは、観測残差 $\mathbf{y}_n – \mathbf{H}_n\mathbf{x}_n^f$ は観測点のズレなのに、それを $\mathbf{K}_n$ によって全格子点へ配っていることです。
では、この $\mathbf{K}_n$ はどう決まるのでしょうか。
6. カルマンゲインの導出
カルマンゲインは、次のように与えられます。
\mathbf{K}_n
=
\mathbf{P}_n^f
\mathbf{H}_n^T
\left(
\mathbf{H}_n
\mathbf{P}_n^f
\mathbf{H}_n^T
+
\mathbf{R}_n
\right)^{-1}
\end{align*}
いきなり見ると難しいですが、これは「予報誤差」と「観測誤差」のバランスから最適な重みを決める式です。
導出の考え方はシンプルです。解析誤差を
\boldsymbol{\varepsilon}_n^a
=
\mathbf{x}_n^a
–
\mathbf{x}_n^t
\end{align*}
と置き、この誤差の分散が最小になるように $\mathbf{K}_n$ を選びます。
更新式に $\mathbf{x}_n^a = \mathbf{x}_n^f + \mathbf{K}_n(\mathbf{y}_n-\mathbf{H}_n\mathbf{x}_n^f)$ を入れ、さらに
\mathbf{x}_n^f
=
\mathbf{x}_n^t
+
\boldsymbol{\varepsilon}_n^f
\end{align*}
\mathbf{y}_n
=
\mathbf{H}_n\mathbf{x}_n^t
+
\boldsymbol{\varepsilon}_n^o
\end{align*}
を代入します。
すると、観測残差は
\mathbf{y}_n
–
\mathbf{H}_n\mathbf{x}_n^f
=
\boldsymbol{\varepsilon}_n^o
–
\mathbf{H}_n
\boldsymbol{\varepsilon}_n^f
\end{align*}
になります。したがって解析誤差は、
\boldsymbol{\varepsilon}_n^a
=
\left(
\mathbf{I}
–
\mathbf{K}_n\mathbf{H}_n
\right)
\boldsymbol{\varepsilon}_n^f
+
\mathbf{K}_n
\boldsymbol{\varepsilon}_n^o
\end{align*}
です。
この解析誤差の共分散を最小にする $\mathbf{K}_n$ を計算すると、上で示したカルマンゲイン
\mathbf{K}_n
=
\mathbf{P}_n^f
\mathbf{H}_n^T
\left(
\mathbf{H}_n
\mathbf{P}_n^f
\mathbf{H}_n^T
+
\mathbf{R}_n
\right)^{-1}
\end{align*}
が得られます。
つまりカルマンゲインは、経験的に決める係数ではありません。解析後の誤差分散を最小にするように導かれる最適な重みです。
7. 1点観測の例でカルマンゲインを成分表示する
ここからは、位置3だけにセンサがある場合のカルマンゲインを実際に計算します。
観測行列は、
\mathbf{H}
=
\begin{pmatrix}
0 & 0 & 0 & 1 & 0 & 0
\end{pmatrix}
\end{align*}
です。
ステップ1:$\mathbf{P}_n^f\mathbf{H}^T$ を計算する
$\mathbf{H}^T$ は、
\mathbf{H}^T
=
\begin{pmatrix}
0 \\
0 \\
0 \\
1 \\
0 \\
0
\end{pmatrix}
\end{align*}
なので、$\mathbf{P}_n^f$ に右から掛けると、位置3に対応する列が取り出されます。
\mathbf{P}_n^f
\mathbf{H}^T
=
\begin{pmatrix}
\sigma_{03} \\
\sigma_{13} \\
\sigma_{23} \\
\sigma_{33} \\
\sigma_{43} \\
\sigma_{53}
\end{pmatrix}
\end{align*}
これは、各位置の誤差が、観測点である位置3の誤差とどれだけ連動しているかを表します。
ステップ2:$\mathbf{H}\mathbf{P}_n^f\mathbf{H}^T+\mathbf{R}$ を計算する
今回は観測が1点だけなので、分母はスカラになります。
\mathbf{H}
\mathbf{P}_n^f
\mathbf{H}^T
+
R
=
\sigma_{33}
+
\sigma_o^2
\end{align*}
$\sigma_{33}$は、位置3のシミュレーション予測の不確かさです。$\sigma_o^2$ は観測誤差分散です。
ステップ3:カルマンゲインを得る
以上を組み合わせると、カルマンゲインは次の $6 \times 1$ ベクトルになります。
\mathbf{K}_n
=
\begin{pmatrix}
\dfrac{\sigma_{03}}{\sigma_{33}+\sigma_o^2} \\
\dfrac{\sigma_{13}}{\sigma_{33}+\sigma_o^2} \\
\dfrac{\sigma_{23}}{\sigma_{33}+\sigma_o^2} \\
\dfrac{\sigma_{33}}{\sigma_{33}+\sigma_o^2} \\
\dfrac{\sigma_{43}}{\sigma_{33}+\sigma_o^2} \\
\dfrac{\sigma_{53}}{\sigma_{33}+\sigma_o^2}
\end{pmatrix}
\end{align*}
この式から、カルマンゲインの意味がはっきり見えます。
- 分子 $\sigma_{i3}$は、位置$i$ と観測点3の誤差がどれだけ連動しているか
- 分母 $\sigma_{33}+\sigma_o^2$ は、観測点3に関する全体の不確かさ
- 観測誤差 $\sigma_o^2$ が大きいほど、観測を信じすぎない
- 共分散 $\sigma_{i3}$ が大きい場所ほど、観測点のズレを強く反映する
8. なぜ1点の観測で全体が修正できるのか
位置3だけにセンサがある場合、更新式は次のようになります。
\mathbf{x}_n^a
=
\mathbf{x}_n^f
+
\mathbf{K}_n
\left(
y_{n,3}
–
x_{n,3}^f
\right)
\end{align*}
ここで、$\mathbf{x}_n^a$、$\mathbf{x}_n^f$、$\mathbf{K}_n$ を成分で全部書くと、次のようになります。
\begin{pmatrix}
x_{n,0}^a \\
x_{n,1}^a \\
x_{n,2}^a \\
x_{n,3}^a \\
x_{n,4}^a \\
x_{n,5}^a
\end{pmatrix}
=
\begin{pmatrix}
x_{n,0}^f \\
x_{n,1}^f \\
x_{n,2}^f \\
x_{n,3}^f \\
x_{n,4}^f \\
x_{n,5}^f
\end{pmatrix}
+
\frac{1}{\sigma_{33}+\sigma_o^2}
\begin{pmatrix}
\sigma_{03} \\
\sigma_{13} \\
\sigma_{23} \\
\sigma_{33} \\
\sigma_{43} \\
\sigma_{53}
\end{pmatrix}
\left(
y_{n,3}
–
x_{n,3}^f
\right)
=
\begin{pmatrix}
x_{n,0}^f
+
\dfrac{\sigma_{03}}{\sigma_{33}+\sigma_o^2}
\left(
y_{n,3}
–
x_{n,3}^f
\right)
\\
x_{n,1}^f
+
\dfrac{\sigma_{13}}{\sigma_{33}+\sigma_o^2}
\left(
y_{n,3}
–
x_{n,3}^f
\right)
\\
x_{n,2}^f
+
\dfrac{\sigma_{23}}{\sigma_{33}+\sigma_o^2}
\left(
y_{n,3}
–
x_{n,3}^f
\right)
\\
x_{n,3}^f
+
\dfrac{\sigma_{33}}{\sigma_{33}+\sigma_o^2}
\left(
y_{n,3}
–
x_{n,3}^f
\right)
\\
x_{n,4}^f
+
\dfrac{\sigma_{43}}{\sigma_{33}+\sigma_o^2}
\left(
y_{n,3}
–
x_{n,3}^f
\right)
\\
x_{n,5}^f
+
\dfrac{\sigma_{53}}{\sigma_{33}+\sigma_o^2}
\left(
y_{n,3}
–
x_{n,3}^f
\right)
\end{pmatrix}
\end{align*}
右端のスカラ量
y_{n,3}
–
x_{n,3}^f
\end{align*}
は、位置3における実測値とシミュレーション予測値のズレです。この1つのズレが、カルマンゲインの各成分を通じて全格子点へ配られます。
この行列式は、6本の更新式を1つにまとめたものです。各行を読むと、次の対応になります。
| 行 | 更新される位置 | 観測残差に掛かる共分散成分 | 意味 |
|---|---|---|---|
| 1行目 | 位置0 | $\sigma_{03}$ | 位置0の誤差が、観測点3の誤差とどれだけ連動するか |
| 2行目 | 位置1 | $\sigma_{13}$ | 位置1の誤差が、観測点3の誤差とどれだけ連動するか |
| 3行目 | 位置2 | $\sigma_{23}$ | 位置2の誤差が、観測点3の誤差とどれだけ連動するか |
| 4行目 | 位置3 | $\sigma_{33}$ | 観測点3自身をどれだけ観測へ寄せるか |
| 5行目 | 位置4 | $\sigma_{43}$ | 位置4の誤差が、観測点3の誤差とどれだけ連動するか |
| 6行目 | 位置5 | $\sigma_{53}$ | 位置5の誤差が、観測点3の誤差とどれだけ連動するか |
つまり、位置0〜5のすべてが同じ観測残差 $y_{n,3}-x_{n,3}^f$を使って更新されます。全体には共通して$1/(\sigma_{33}+\sigma_o^2)$が掛かり、そのうえで各位置ごとの共分散成分$\sigma_{03}, \sigma_{13}, \ldots, \sigma_{53}$ によって修正量が決まります。観測点3と誤差が強く連動する場所ほど、大きく修正されます。
位置1にはセンサがありません。それでも、$\sigma_{13}$ が大きければ、位置3の観測残差を使って位置1も修正されます。
つまり、データ同化が使っているのは観測値そのものだけではありません。シミュレーションが持っている「誤差の空間的なつながり」も使っています。
これが、限られたセンサ観測から空間全体の分布を改善できる理由です。
9. まとめ
この記事では、データ同化の基本を1次元格子モデルで説明しました。
- シミュレーションは空間分布を持つが、誤差を含む
- 観測は現実に近いが、場所が限られ、観測誤差も含む
- 予測値は $\mathbf{x}^f = \mathbf{x}^t + \boldsymbol{\varepsilon}^f$ と書ける
- 観測値は $\mathbf{y} = \mathbf{H}\mathbf{x}^t + \boldsymbol{\varepsilon}^o$ と書ける
- カルマンゲインは、観測残差をどの格子点へどれだけ配るかを決める
- その重みは、予報誤差共分散と観測誤差共分散から導かれる
式としてまとめると、まずカルマンゲインは次のように計算します。
\mathbf{K}_n
=
\mathbf{P}_n^f
\mathbf{H}_n^T
\left(
\mathbf{H}_n
\mathbf{P}_n^f
\mathbf{H}_n^T
+
\mathbf{R}_n
\right)^{-1}
\end{align*}
ここで、$\mathbf{P}_n^f$ はシミュレーションの予報誤差共分散、$\mathbf{R}_n$ は観測誤差共分散です。つまり、カルマンゲインは「シミュレーションの不確かさ」と「観測の不確かさ」のバランスから決まります。
そして、このカルマンゲインを使って解析値、つまり観測を取り込んだ後の推定値を求めます。
\mathbf{x}_n^a
=
\mathbf{x}_n^f
+
\mathbf{K}_n
\left(
\mathbf{y}_n
–
\mathbf{H}_n
\mathbf{x}_n^f
\right)
\end{align*}
この式の中の
\mathbf{y}_n
–
\mathbf{H}_n
\mathbf{x}_n^f
\end{align*}
が観測残差です。つまり、「実測値」と「シミュレーションが予測したセンサ値」のズレです。カルマンゲインは、このズレを各格子点へどの割合で配るかを決めます。
データ同化とは、単に「実測値でシミュレーションを補正する」だけの技術ではありません。
シミュレーションの誤差構造と観測データを組み合わせて、最も確からしい状態を推定するための統計的な枠組みです。
次回以降は、この考え方をもとに、最適補間法(OI)、カルマンフィルタ、EnKF へと順番に発展させていきます。




