こんにちは(@t_kun_kamakiri)(‘◇’)ゞ
本日はPandasというライブラリを使って表形式のデータの処理の方法を紹介します。
表形式と言えばExcelでの操作に慣れている人が多いかと思いますが、同じこともしくはそれ以上のことがPythonのPandasライブラリを使ってできます。
- Python初心者でPandasを使い始めている人
- Pandasを使ったDataFrameのを使いこなしたい人
Pandasには配列の次元によって以下のようにオブジェクトが区別されています。
難しいことはさておき・・・・・
下の表のようにExcelの表全体をDataFrameと言い、各列(1次元配列)をSeriesと考えていればオッケーですね(^^)
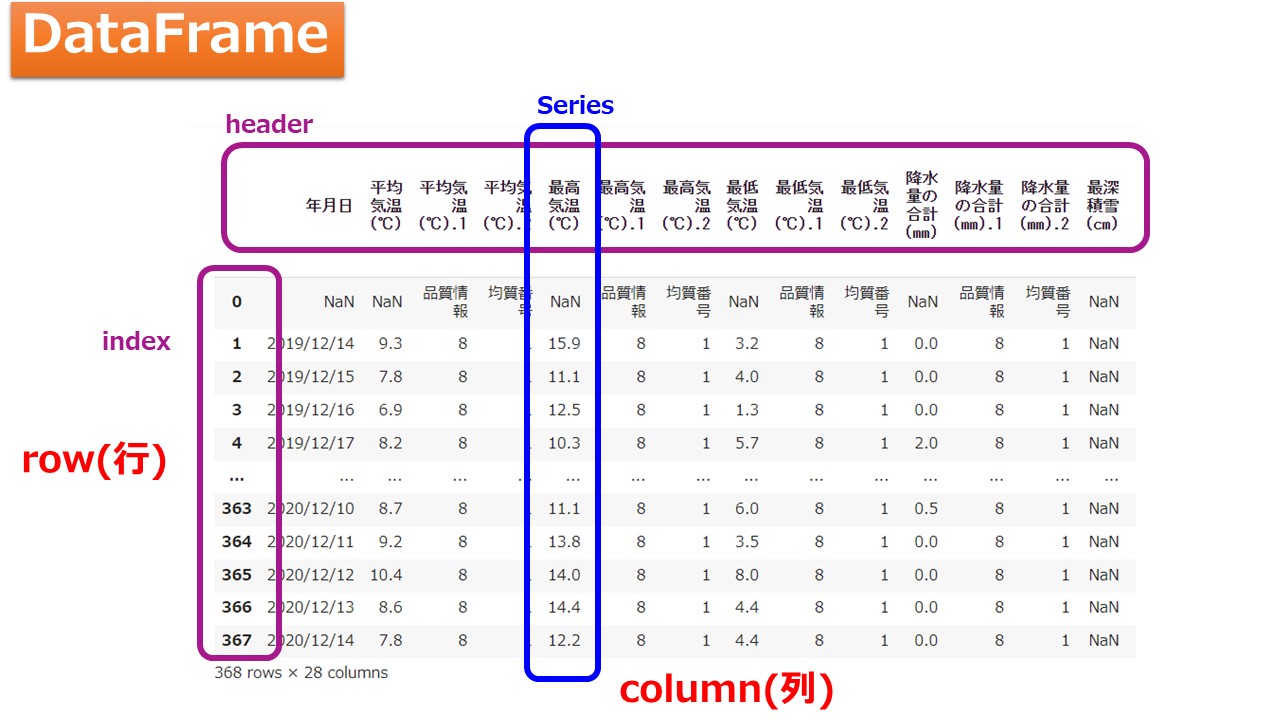
また、列をcolumn(カラム)と言い、行をrow(ロー)もしくはレコードと言ったりします。1番上の列のタイトルに相当する行はheader(ヘッダー)と言います。
pandasを使ったデータの処理に属性を使うのですが、これらの用語がそのまま属性の名前になっており、よく使うため用語をよく覚えておきましょう。
データの前処理はとても重要な工程であり、その工程においてPythonを使う限り必ず使うのがPandasライブラリです。
日本語の書籍も充実しているため1冊手元に置いておく辞書代わりとして使えます。

Seriesオブジェクト
1次元のデータを取り扱うSeriesについて学びます。
Seriesについての使い方は公式ドキュメントを参考にしながら学ぶことをお勧めします。
ものすごく多くの属性が用意されているので、とても覚えきれるものではありませんが、本記事ではよく使うものを紹介します。

まずは必要なライブラリをインポートしましょう。
|
1 2 |
import pandas as pd import numpy as np |
pandasというライブラリを「pd」と略してインポートし、numpyライブラリを「np」と略してインポートしておきます。
では、numpyの配列から1次元配列のSeriesオブジェクトを生成してみましょう。
indexを指定する
まずはindexを指定してSeries型を作ってみましょう。
|
1 2 3 4 5 6 |
# indexを指定 a = np.linspace(0,5,6) index = ['a','b','c','d','e','f'] df = pd.Series(a,name='data', index=index ) df |
- a = np.linspace(0,5,6)で0~5を6分割したndarray(N-dimensinal array:N次元配列)配列を生成
- index = [‘a’,’b’,’c’,’d’,’e’,’f’]でSeriesの1次元配列のindexをリスト型で生成しています。
その後で、 pd.Series(a,name=’data’, index=index )として引数にndarray配列とindexに先ほどのリスト型を入れています。
【結果】
|
1 2 3 4 5 6 7 |
a 0.0 b 1.0 c 2.0 d 3.0 e 4.0 f 5.0 Name: data, dtype: float64 |
このように1次元配列のデータを作ることができました。
辞書型でSeriesを作る
次は辞書型をSeriesの引数に渡して1次元配列を作成していましょう。
|
1 2 3 4 5 6 7 8 9 |
# 辞書型で渡す dct ={ 'a':1, 'b':2, 'c':3, 'd':4 } df = pd.Series(dct,name='data') df |
【結果】
|
1 2 3 4 5 |
a 1 b 2 c 3 d 4 Name: data, dtype: int64 |
このようにして辞書型を介してデータを1次元配列を作ることができます。
属性(attributes)
pandasのSeriesにはデータを取り扱うための属性(attributes)が多く用意されています。
ここではよく使う属性について紹介します。
name属性
name属性を使うことででデータに名前を付けることができます。
データに名前を付ける
name属性を使うことで1次元配列の名前を取得することができます。
|
1 2 3 4 5 6 7 8 9 10 |
# 辞書型で渡す dct ={ 'a':1, 'b':2, 'c':3, 'd':4 } df = pd.Series(dct,name='data') df.name |
Series(dct,name=’data’)としてデータの名前を「data」としました。
【結果】
|
1 |
data |
データの名前の更新
また、データの名前を更新するには以下のように記述します。
|
1 2 |
df.name = 'data_new' df.name |
【結果】
|
1 |
data_new |
index属性
index属性を使うことでSeriesのindexを操作することができます。
indexを更新する
1次元配列のデータの各行にindexとしてデフォルトでは数字が0から割り振られています。
まずはリストをSeriesに入れてみます。
|
1 2 |
df = pd.Series([1,2,3,4,5,6,7,8,9,10]) df |
【結果】
|
1 2 3 4 5 6 7 8 9 10 11 |
0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 dtype: int64 |
このように1列目はindexが0からはじまる整数で割り当てられています。
さきほど見たように辞書型をSeriesに入れるとindexが辞書型のキーとして割り当てられます。以下のようにindex属性を確認してみましょう。
|
1 2 3 4 5 6 7 8 9 10 |
# 辞書型で渡す dct ={ 'a':1, 'b':2, 'c':3, 'd':4 } df = pd.Series(dct,name='data') df.index |
【結果】
|
1 |
Index(['a', 'b', 'c', 'd'], dtype='object') |
indexの値を取り出したい場合は、さらに「.(ドット)」でつなげることで値を取得できます。
|
1 2 |
print(df.index, type(df.index)) print(df.index.values, type(df.index.values)) |
【結果】
|
1 2 |
Index(['a', 'b', 'c', 'd'], dtype='object') <class 'pandas.core.indexes.base.Index'> ['a' 'b' 'c' 'd'] <class 'numpy.ndarray'> |
indexを更新する
属性にリスト型を代入することでindexを更新することができます。
|
1 2 |
df.index = ['a_new', 'b_new', 'c_new', 'd_new'] df.index |
【結果】
|
1 |
Index(['a_new', 'b_new', 'c_new', 'd_new'], dtype='object') |
values属性
index属性はvalues(値)に関連付けられたキーを所得するSeriesの属性でしたが、values属性を使うことで1次元配列のデータを取得することができます。
|
1 2 3 4 5 6 7 8 9 10 |
# 辞書型で渡す dct ={ 'a':1, 'b':2, 'c':3, 'd':4 } df = pd.Series(dct,name='data') df.values |
【結果】
|
1 |
array([1, 2, 3, 4]) |
shape属性
shape属性を使うことでデータの大きさを確認することができます。
|
1 |
df.shape |
【結果】
|
1 |
(4,) |
以上のようにpandasのSeriesを使うことで1次元配列のデータを取り扱うことができました。
DataFrameオブジェクト
次に2次元配列を持ったDataFrameを取り扱います。
DataFrameは以下のようにExcelの表のように縦と横にデータがぎっしり詰まっている2次元配列のデータです。
まずは必要なライブラリをインポートしましょう。
|
1 2 |
import pandas as pd import numpy as np |
panasのDataFrameはnumpyとの相性が良く、以下のように0~11の数字を2次元配列にしたものをDataFrameに入れることで表が作成できます。
まずは、numpyを使って2次元配列を作ります。
|
1 2 3 |
a = np.arange(12).reshape(3, 4) a |
【結果】
|
1 2 3 |
array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) |
これをDataFrameに入れます。
|
1 2 3 |
df = pd.DataFrame(a) df |
【結果】

簡単にデータフレームが作成できましたね。
indexとheaderを指定
indexやheaderを指定することもできます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# indexを指定 data = [] a = np.array([ [1,2,3], [4,5,6], [7,8,9] ]) index = ['a','b','c'] columns = ['x','y','z'] df = pd.DataFrame(a, index=index, columns=columns) df |

辞書型にしてDaraFrameに入れる
先ほどのようにindexを別で指定することもできますが、下記のように辞書型をDataFrameに入れることで、辞書型のキーがDataFrameのheaderになります。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 辞書型を設定してデータフレームを作成 dct ={ 'a':[1,2,3,4], 'b':[5,6,7,8], 'c':[9,10,11,12], 'd':[13,14,15,16] } df = pd.DataFrame(dct) df |
【結果】

リスト型の中に辞書型を設定してデータフレームを作成
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# リスト型の中に辞書型を設定してデータフレームを作成 list_dct = [ { 'a':1, 'b':2, 'c':3, 'd':4 }, { 'a':5, 'b':6, 'c':7, 'd':8 }, { 'a':9, 'b':10, 'c':11, 'd':12 }, { 'a':13, 'b':14, 'c':15, 'd':16 }, ] df = pd.DataFrame(list_dct) df |
【結果】

こちらを応用して大きなDataFrameをfor文で作ってみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
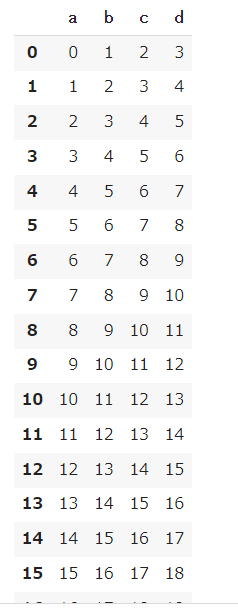
# リスト型の中に辞書型を設定してデータフレームを作成 # 空のリストを用意 list_dct = [] for i in range(24): a = i+0 b = i+1 c = i+2 d = i+3 # 辞書型を作る dct = { 'a':a, 'b':b, 'c':c, 'd':d } list_dct.append(dct) df = pd.DataFrame(list_dct) df |
【結果】
はじめの数行(10行)だけを表示
行数が多いDataFrameに対しては、行数が多すぎると見にくいため、最初の数行だけを表示する属性を使います。
|
1 |
df.head() |
【結果】

head属性を使うことで最初の5行だけを表示することができました。
もし、最初の10行だけを見たい場合は引数に「10」と指定することで、10行分表示することができます。
|
1 |
df.head(10) |
【結果】
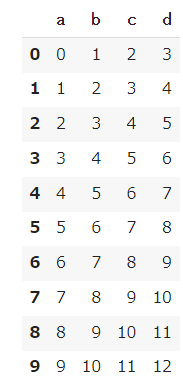
最後の数行(10行)だけを取り出す
最後の数行だけを取り出したい場合には「tail」を使います。
引数に抜き出したい行数を指定するができます。
|
1 |
df.tail(10) |
【結果】

データの情報を確認
Pandasのinfoメソッドを使うことで、行数・列数やデータの型、メモリ使用量を確認することができます。
それだけではなく、大量のデータの中の欠損値ではない要素の数を知ることができます。
|
1 2 |
# データの型、メモリ使用量などの情報を確認 df.info() |
【結果】

headerとindexを抜き出す
DataFrameのheaderとindexを取り出しましょう。
headerとindexは以下の部分のことですね。
先ほど同様にDataFrameをfor文で作ってみましょう。
※コピペでOKです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# リスト型の中に辞書型を設定してデータフレームを作成 # 空のリストを用意 list_dct = [] for i in range(24): a = i+0 b = i+1 c = i+2 d = i+3 # 辞書型を作る dct = { 'a':a, 'b':b, 'c':c, 'd':d } list_dct.append(dct) df = pd.DataFrame(list_dct) df |
【結果】
indexを取り出します。
|
1 |
df.index |
【結果】
|
1 |
RangeIndex(start=0, stop=24, step=1) |
次に、header部分を取り出します。
|
1 |
df.columns |
【結果】
|
1 |
df.columns |
これでDataFramの情報の表示の仕方についてまなぶことができました。
DataFramのデータを取り扱う
ここからは、DataFrameに条件を加えて必要なデータを取り出したり、取り出したデータを加工する操作について学んでいきます。
まずは、取り扱うDataFrameを確認しましょう。
|
1 |
df |
1つの列のデータを取り出す
a列のデータを取り出してみましょう。
|
1 |
df['a'] |
【結果】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10 11 11 12 12 13 13 14 14 15 15 16 16 17 17 18 18 19 19 20 20 21 21 22 22 23 23 Name: a, dtype: int64 |
1つの列のデータを取得したい場合はdf[‘指定の列名’]とすればよいです。
1つの行を取り出すのであれば、dfの列名が属性として登録されるため以下のような書き方でも可能です。
|
1 |
df.a |
【結果】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10 11 11 12 12 13 13 14 14 15 15 16 16 17 17 18 18 19 19 20 20 21 21 22 22 23 23 Name: a, dtype: int64 |
複数行のデータを取り出す
次に、指定した複数の列のデータを取り出したい場合についてです。
1つの列のデータの場合はdf[‘a’]のように書きましたが、df[リスト型]として、リスト型に文字列で[‘a’, ‘b’]と複数の列名を指定します。
|
1 2 |
# 複数列取り出したい場合はリストにする df[['a','b']] |
【結果】

補足ですが、先ほどの1つの列のデータを取得する場合は、今回のようにリスト型として指定することもできます。
|
1 |
df[['a']] |
どうして角括弧[]が2つあるのかと疑問に思うかもしれませんが、リスト型が入ってdf[リスト型]という構造になっていると理解すれば良いです。
【結果】

行と列を指定する:iloc
先ほどのような列名を指定する場合もあれば、今回のように行と列をことでデータを取り出すことができます。
|
1 2 |
# 行と列を指定 df.iloc[1:10,1:3] |
【結果】

ilocのiがindex、locがlocation(場所)の略なので、どのindexの場所を取り出すか指定するものですね。
ちょっとややこしいので、どうなっているのかを絵で解説します。

注意ですが指定した行と列はindexが0から開始されるので、1行目はindexが0に対応します。ちょっとややこしいですが、indexが0から始まるのかと覚えたおかなければ間違ったデータを取得してしまいますのでご注意を!
また、どこまで取り出すかも指定したindexより手前なので指定したindexより1つ手前のデータまでを取り出すという点もややこしいですが、そういった仕様であることを覚えておきましょう。
行と列を指定する:loc
ilocとlocがややこしいですが、locを指定することで行名や列名で指定してデータを取り出すことができます。
|
1 2 |
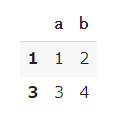
# 行と列のラベルを指定 df.loc[[1,3],['a','b']] |
【結果】
今回はindexが数字なので以下のようにしても良いです。
|
1 2 |
# 行と列のラベルを指定 df.loc[1:10,['a','b']] |
【結果】

ピンポイントで値を取り出す:at
indexは数字なのでindexの数を指定し、列名は文字列で指定することでほしい値を取得できます。
|
1 2 |
# ピンポイントで値を取り出す df.at[10,'b'] |
【結果】
|
1 |
11 |
また、少し前で示したようにindexが文字の場合の例も見ておきましょう。
復習ですが文字をindexにする場合は以下のようにコードを書いてDataFrameを用意します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# indexを指定 data = [] a = np.array([ [1,2,3], [4,5,6], [7,8,9] ]) index = ['a','b','c'] columns = ['x','y','z'] df_test = pd.DataFrame(a, index=index, columns=columns) df_test |
【結果】

そして、a行のy列の値(つまり2)を取得したい場合は以下のように書けばよいです。
|
1 |
df_test.at['a','y'] |
【結果】
|
1 |
2 |
ピンポイントで値を取り出す:iat
|
1 2 |
# ピンポイントで値を取り出す df.iat[10,1] |
【結果】
|
1 |
11 |
DataFrameの加工
ここまではDataFrameからデータを取り出すことを行いましたが、実際にはデータを加工して使うことが多いです。
DataFrame動詞の足し算
まずは2つのDataFrameを用意しましょう。
|
1 2 3 4 5 6 7 |
a = np.random.randint(1,10,30).reshape(10,3) b = np.random.randint(1,10,30).reshape(10,3) columns = ['a', 'b' ,'c'] df_1 = pd.DataFrame(a, columns=columns) df_2 = pd.DataFrame(b, columns=columns) |
【結果】

どうなっているのか分からない人のために、解説を加えます。
np.random.randint(low, high=None, size=None)とすることで、lowからhighで指定した範囲の一様分布な確率で、sizeの数だけndarray配列を作ってくれます。
つまり、今回は1~10までの数字を等確率で30個数字をランダムに選択しています。
|
1 |
np.random.randint(1,10,30) |
【結果】
|
1 2 |
array([7, 4, 3, 6, 8, 5, 7, 7, 2, 4, 5, 7, 6, 6, 8, 3, 2, 5, 9, 7, 1, 4, 4, 8, 8, 5, 2, 5, 1, 9]) |
このようになってものを10行3列の配列に変えます。
|
1 |
np.random.randint(1,10,30).reshape(3,10) |
【結果】
|
1 2 3 |
array([[3, 8, 5, 2, 8, 6, 7, 1, 4, 4], [1, 1, 8, 2, 4, 9, 2, 6, 6, 4], [6, 1, 6, 4, 6, 5, 4, 9, 9, 6]]) |
2つのDataFrameであるdf_1とdf_2ができたので、各要素で足し算を行いましょう。
|
1 2 |
# データフレーム同士の足し算 df_1 + df_2 |
【結果】
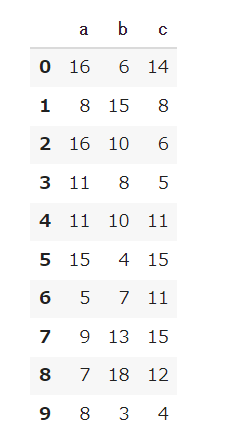
列の追加
df_1に次の新しいデータを追加してみましょう。
新しい列の名前はdf_1「a+c」として、はdf_1のa列とdf_1のc列の出し残として追加します。
|
1 2 3 |
# 列の追加 df_1['a+c'] = df_1['a'] + df_1['c'] df_1 |
【結果】
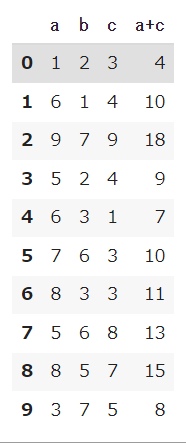
行の削除
次は行の削除を行いましょう。
行の削除にはdropメソッドを使います。
|
1 2 |
# 行の削除 df_1.drop(5, axis=0) |
【結果】
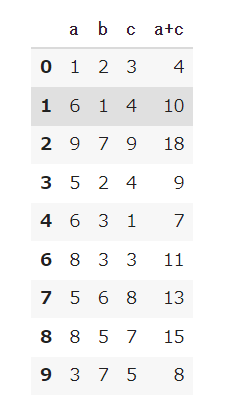
df.drop(5, axis=0)としてことでindexが5の行が削除されました。
しかし、これは削除を行ったものを表示しただけでdf_1そのものは何も変わっていません。念のためのdf_1を確認しましょう。
|
1 2 |
# df_1は変わっていない df_1 |
【結果】
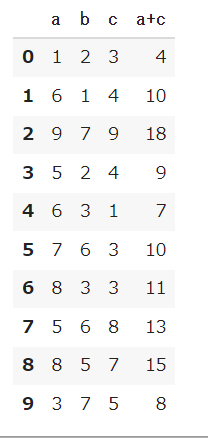
列の削除
列を削除したい場合は、dropメソッドの引数でaxis=1と指定すれば良いです。
また、df_1で指定した列を削除した結果をDataFrameに反映したい場合は、inplace=Trueとしてやれば良いです。
- axis:0だと行を削除。1だと列を削除
- inplace:TrueだとDataFrameの上書き
|
1 2 3 |
# 列の削除 df_1.drop('a+c', axis=1, inplace=True) df_1 |
【結果】

条件にデータを絞る
DataFrameに比較演算子をすることで、各要素がTrueかFalseになります。
|
1 |
df_1 > 5 |
【結果】

この比較演算子によって出てきたデータをDataFrameに入れることで、条件にあったデータだけを数字で表示してくれます。
|
1 |
df_1[df_1 > 5] |
【結果】
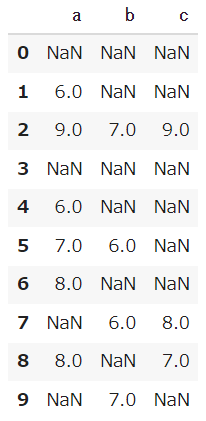
どの列に対して条件を課すのかを示すことで、その列が条件に満たすものだけを表示してくれます。
|
1 |
df_1[df_1['c'] >5] |
【結果】
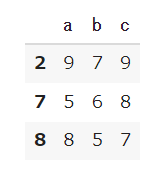
※これは以下のようにlocを使っても同じ結果になります。
|
1 |
df_1.loc[df_1['c'] > 5] |
列に条件をかしつつ、抜き出したい列を指定したい場合は以下のように書きます。
|
1 |
df_1.loc[df_1['b'] > 5,['a','b']] |
【結果】

条件を満たすものに値を入れる
|
1 |
df_1.mask(df_1['a']>5, '5より大きい') |
【結果】

条件を満たさないものに値を入れる
|
1 2 3 |
# 条件に外れたものに値を入れる df_1.where(df_1 >5, '条件を満たさない') |
【結果】

順番の並べ替え
df_1のa列を昇順(大きい値順)に並べ替えます。
|
1 |
df_1.sort_values('a', ascending=False) |
【結果】

降順(小さい値順)に足したい場合は、 ascending=Trueにすればできます。
上の例だとa列を昇順になったのですが、indexも並び変えられてしまいます。
もし、indexは並び変えたくない場合はreset_indexの引数にdrop=Trueと書けばよいです。
|
1 |
df_1.sort_values('a', ascending=False).reset_index(drop=True) |
【結果】

2つのデータを結合する
2つのDataFrameを結合する場合はconcatメソッドを使います。
ただし、列(下側に追加する)か行(横側に追加する)かはaxisで指定する必要があります。デフォルトだとaxis=0であるため、列側にもうひとつのDataFrameが結合されます。
|
1 2 |
df_con = pd.concat([df_1,df_2]) df_con |
axisを指定しない場合はaxis=0となり以下の結果となります。
【結果】
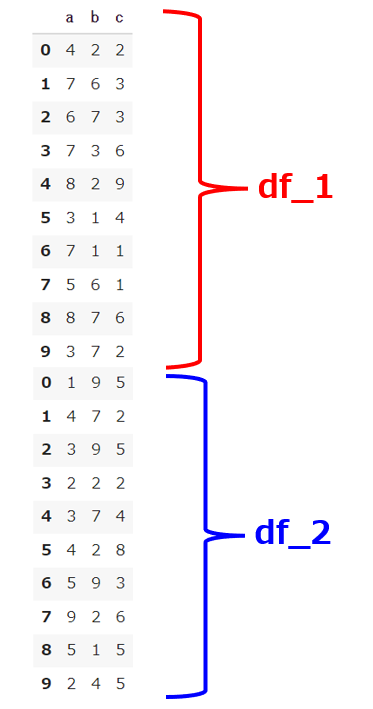
行に追加したい場合はaxis=1とします。
|
1 2 |
df_con = pd.concat([df_1,df_2], axis=1) df_con |
【結果】
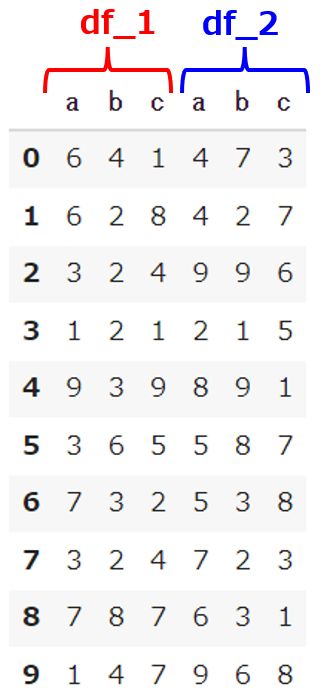
DataFrameの色々な結合の仕方
DataFrameの結合の仕方はconcat以外にもmergeメソッドというのがあります。
2つの適当なDataFrameを作って試してみましょう。
まずは1つ目のDataFrameを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# リスト型の中に辞書型を設定してデータフレームを作成 # 空のリストを用意 list_dct = [] for i in range(10): e = i+0 f = i+1 g = i+2 h = i+3 # 辞書型を作る dct = { 'e':e, 'f':f, 'g':g, 'h':h } list_dct.append(dct) df1 = pd.DataFrame(list_dct) df1 |
【結果】
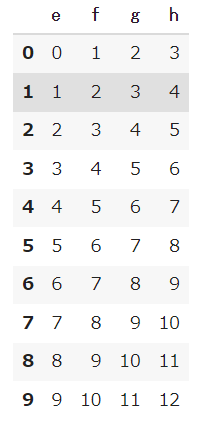
もうひとつのDataFrameを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# リスト型の中に辞書型を設定してデータフレームを作成 # 空のリストを用意 list_dct = [] for i in range(10): d = i-2 c = i-1 e = i+3 f = i+10 g = i+20 h = i+30 # 辞書型を作る dct = { 'c':c, 'd':d, 'e':e, 'f':f, 'g':g, 'h':h } list_dct.append(dct) df2 = pd.DataFrame(list_dct) df2 |
【結果】
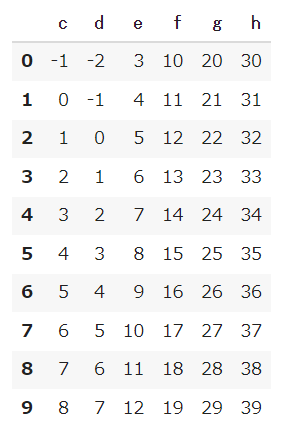
共通している列名「e」について結合します。
ただし、e列が同じ値の場合はそのまま横に結合します。
|
1 2 |
df_merge = pd.merge(df1,df2,on='e', how='outer') df_merge |
【結果】
以下のように結合されます。
ただし、how=’outer’としているためe列の共通していない要素はNanと表示されます。
共通していない部分もDataFrameのレコード(行)として残るということですね。
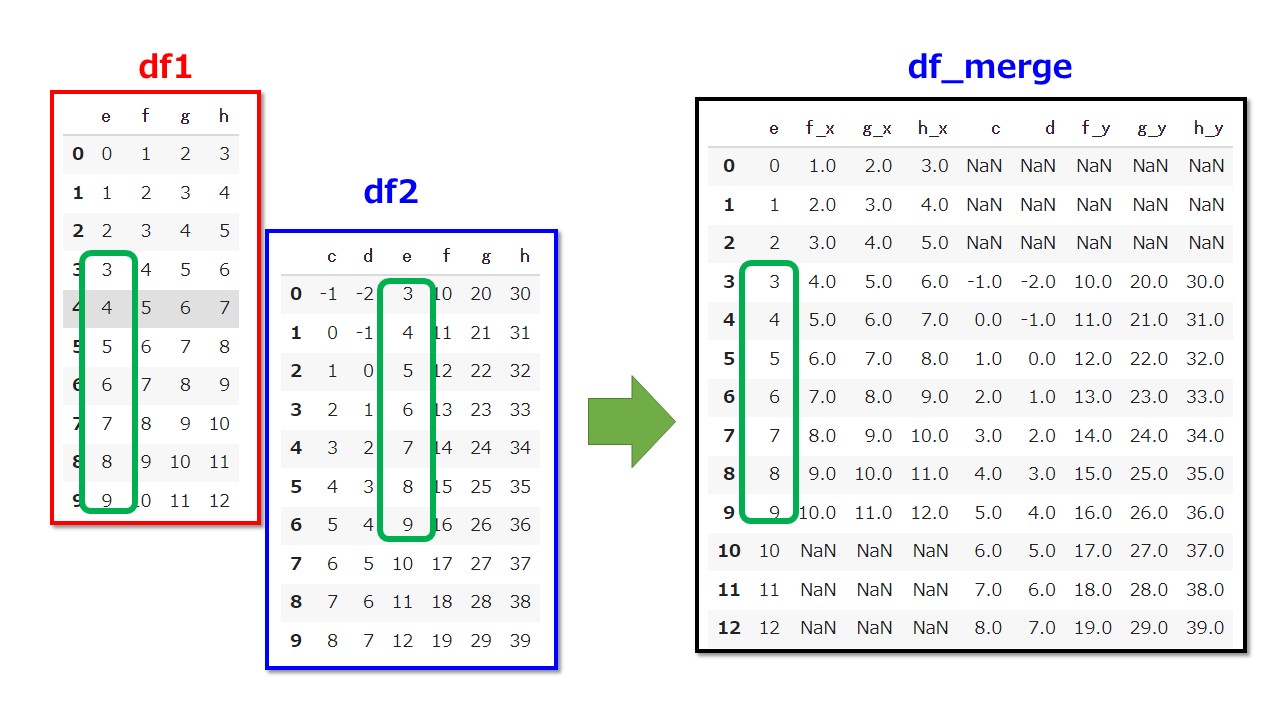
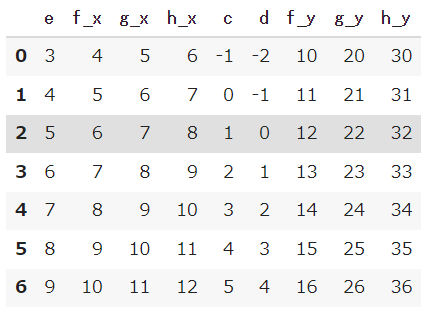
共通している部分だけを結合する場合は、how=’inner’とすれば良いです。
|
1 2 |
df_merge = pd.merge(df1,df2,on='e', how='inner') df_merge |
【結果】
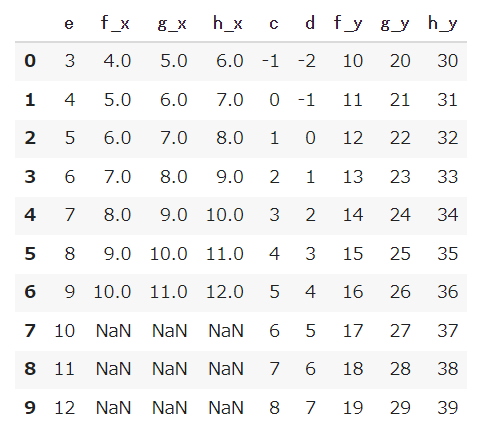
「how=」でどこを基準にして結合するかをしているだけなので、「how=’right’」として右側のDataFrame(df2)を基準にして結合することもできます。
|
1 2 |
df_merge = pd.merge(df1,df2,on='e', how='right') df_merge |
【結果】
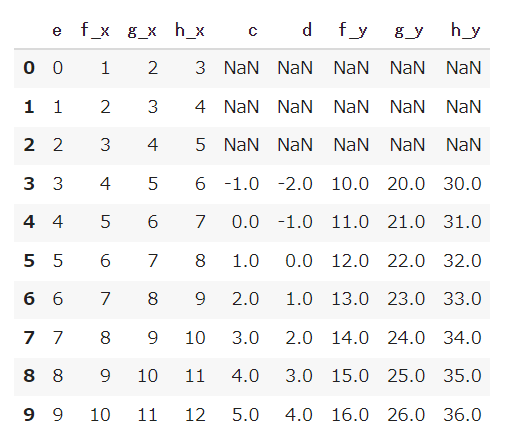
「how=left’」としてDataFrame(df1)を基準にして結合することもできます。
|
1 2 |
df_merge = pd.merge(df1,df2,on='e', how='left') df_merge |
【結果】
NaNを別の要素に置き換える
NaNはデータとして取り扱うことができないので別の値に置き換えることがしばしばあります。その時に使うメソッドがfillnaです。
では、先ほど結合したdf_mergeにはNaNがあったため別の要素に置き換えてみましょう。
|
1 |
df_merge.fillna('NaNを置き換えた') |
【結果】
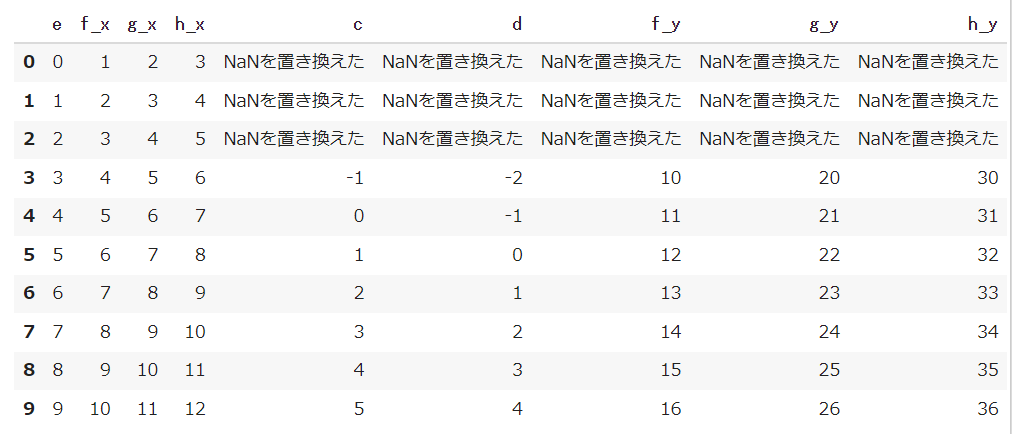
NaNがあったとしてもデータ量を減らさないようにしたい場合は、とにかく統計量には影響を与えないようためにNaNのところに平均値を入れておく場合があります。
DataFrameの列の平均はmeanメソッドで計算できます。
|
1 |
df_merge.mean() |
【結果】
|
1 2 3 4 5 6 7 8 9 10 |
e 4.5 f_x 5.5 g_x 6.5 h_x 7.5 c 2.0 d 1.0 f_y 13.0 g_y 23.0 h_y 33.0 dtype: float64 |
では、NaNの部分を平均値に置き換えてみましょう。
|
1 2 |
df_merge = df_merge.fillna(df_merge.mean()) df_merge |
【結果】
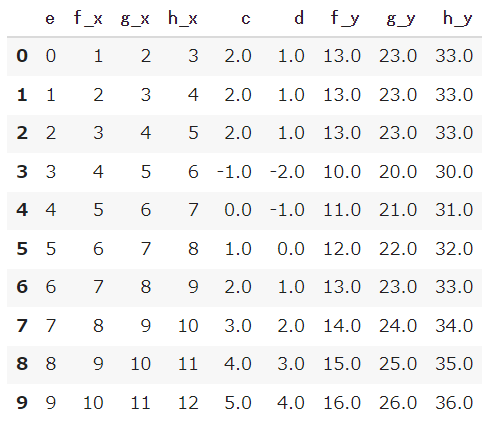
DataFrameの要素のデータの型を変更する
データの要素の方を変えたい場合はastypeメソッドの引数にデータの型を指定して型を変更することができます。
df_mergeのf_y、g_y、h_yは浮動小数点型(float型)になっているので、整数型(int型)に変更してみましょう。
|
1 |
df_merge.astype(int) |
【結果】
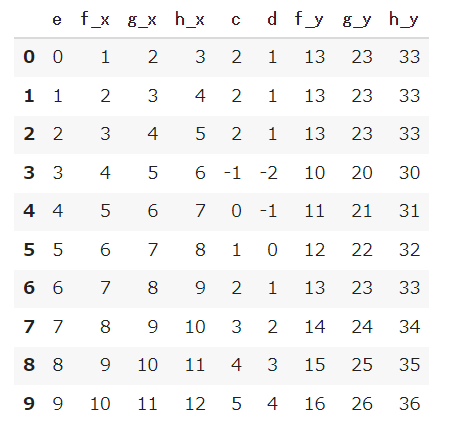
グルーピングして統計量を計算する
DataFrameの要素の中には同じカテゴリーにできるものがあり、その統計量を知りたい場合があります。
以下のように「x,y,z」しかない要素を追加しましょう。
|
1 2 |
df_merge['common'] = ['x','x','y','y','z','z','x','x','z','z'] df_merge |
【結果】

例えば「xが男性」「yが女性」「zがそれ以外(ニューハーフなど)」としましょう。
x,y,zをカテゴリーにグルーピングをして最大値や平均値や標準偏差を見たい場合にはgroupeメソッドを使い、.(ドット)でつないで見た統計量を指定します。
グルーピングの最大値を計算
|
1 |
df_merge.groupby('common').max() |
【結果】
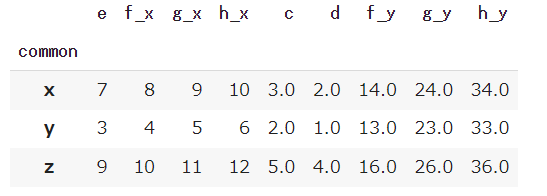
グルーピングの平均値を計算
|
1 |
df_merge.groupby('common').mean() |
【結果】
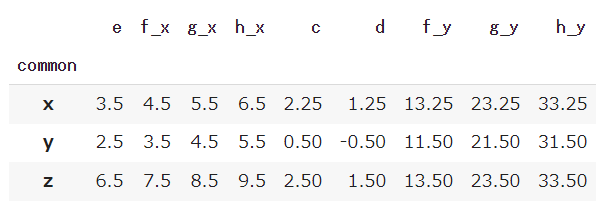
グルーピングの標準偏差を計算
|
1 |
df_merge.groupby('common').std() |
【結果】

DataFrameの統計量を見たい場合:describe
列ごとの統計量を見たい場合はdescribeメソッドを使うと便利です。
※数値以外のところは計算はできないため表示してくれません。
|
1 |
df_merge.describe() |
【結果】
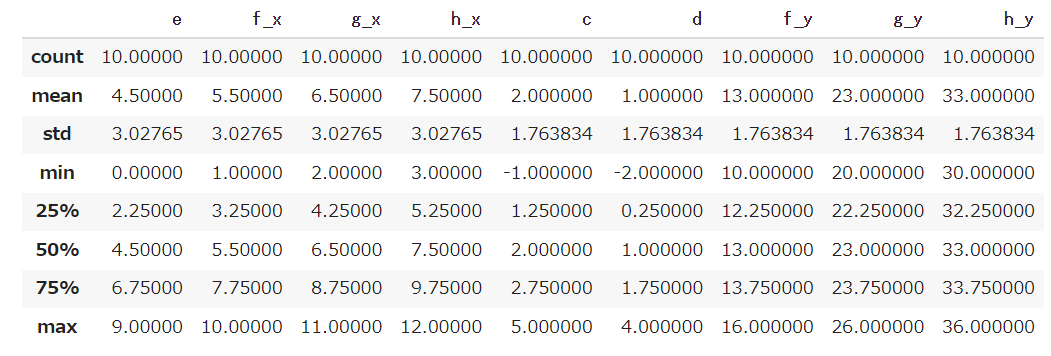
まとめ
pandasの属性やメソッドで使いそうなものを一通り紹介しました。
これらは使っていれば自然と覚えるものなので、覚えきれなていない場合は「毎回、調べて使えればいいや」というくらいで良いと思います。
Seriesオブジェクト(1次元配列)
- df.name
- df.index
- df.shape
- df.values
- df.dtype
DataFrameオブジェクト(2次元配列)
- df.head()
- df.tail()
- df.info()
- df.values
- df.index
- df.columns
- df.dtypes
- df[[‘a’,’b’]]
- df.loc[1:10,[‘a’,’b’]]
- df.iloc[1:10,:2]
- df.at[10,’b’]
- df.iat[10,1]
- df[‘a+d’] = df[‘a’] + df[‘d’]
- df.drop(5, axis=0)
- df.drop(‘a+d’, axis=1, inplace=True)
- df[df[‘d’] > 10]
- df.loc[df[‘d’] > 10,[‘a’,’b’]]
- df.where(df >10, ‘条件を満たさない’)
- df.mask(df[‘d’]>10, ’10より大きい’)
- df.sort_values(‘d’, ascending=False)
- df.sort_index(ascending=True)
- df_con = pd.concat([df,df1], axis=1)
- df_con = pd.concat([df,df1],join=’inner’)
- df_merge = pd.merge(df,df1,on=’a’, how=’outer’)
- df_merge = pd.merge(df,df1,on=’a’, how=’inner’)
- df_merge.fillna(‘NaNを置き換えた’)
- df_merge.astype(int)
- df_merge.groupby(‘common’).max()
- df_merge.groupby(‘common’).mean()
- df_merge.groupby(‘common’).std()