【Python入門講座】タイタニック号のデータ分析

こんにちは(@t_kun_kamakiri)(‘◇’)ゞ
前回の記事ではPandasの基礎的な使い方の記事を書きました。
本日はPandasを使った実践的な内容をやっていきます。
kaggleで有名なタイタニック号のデータを使ったデータ分析入門講義をまとめました。
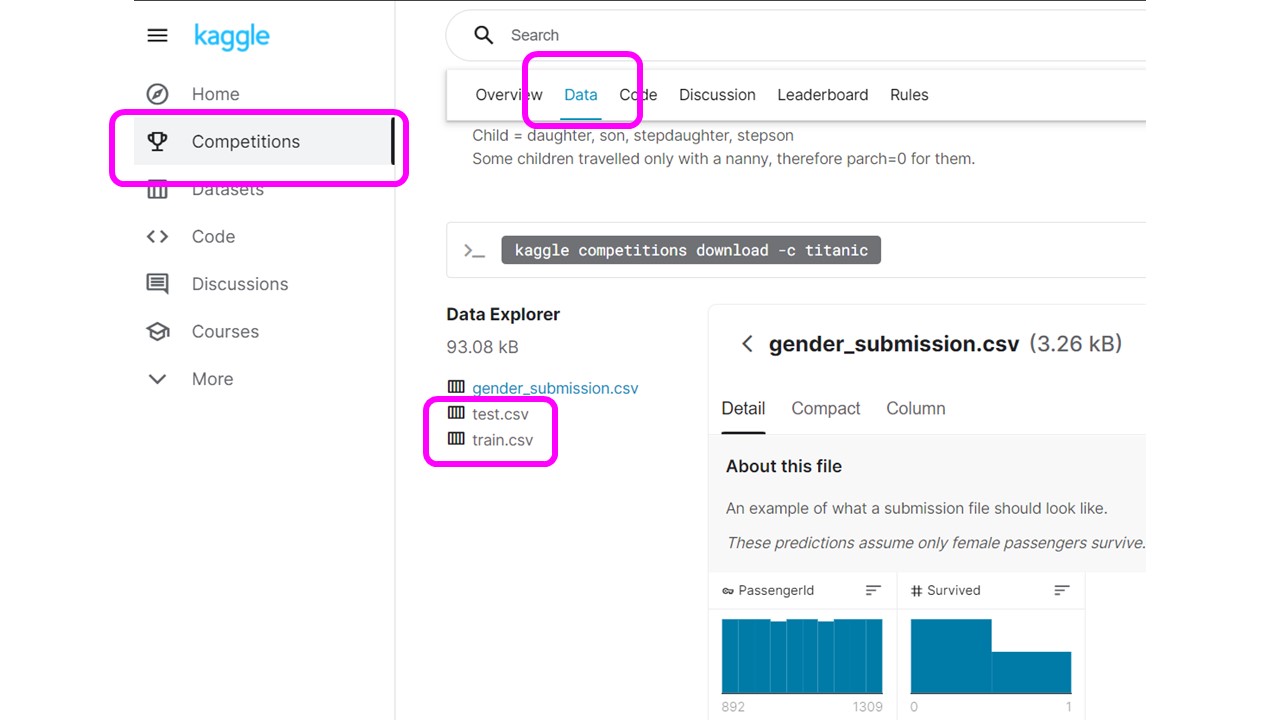
kaggleの利用には無料アカウント登録が必要ですので、アカウントをお持ちでない方はこちらから登録をしましょう。
データはkaggleで公開されているタイタニック号の乗客のリストです。
こちらのサイトからcsvデータをダウンロードすることができますので、本記事の内容に入る前にダウンロードしておきましょう。
ダウンロードするのは以下のcsvデータです。
- train.csv:学習用のデータ(今回こちらを使う)
- test.csv:検証用のデータ
train.csv(学習用のデータ)でデータの傾向を機械学習によりモデル化し、test.csvによって機械学習でモデル化されたモデルがどれくらいの精度出ているのかを検証するものです。今回は機械学習をするのではなくデータを使ったデータ分析を行うため、train.csvファイルを使います。
本記事ではJupyter labを使います。
こちらのサイトからtrain.csvをダウンロードしたらJupyter labと同じ階層にファイルを保存しましょう。
- Python初心者でPandasを使い始めている人
- Pandasを使ったDataFrameのを使いこなしたい人
- Pandasを使って実践的な内容をしてみたい人
Pandasの基礎については以下の記事で勉強ができますので事前に読んでおくことをお勧めします♪
データの読み込み
まずは必要なライブラリをインポートしましょう。
|
1 2 3 4 |
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import numpy as np |
次に、kaggleよりダウンロードしたcsvファイルを読み込みましょう。
|
1 2 |
df_taitanic = pd.read_csv('./train.csv') df_taitanic |
以下のようにデータが読み込まれます。
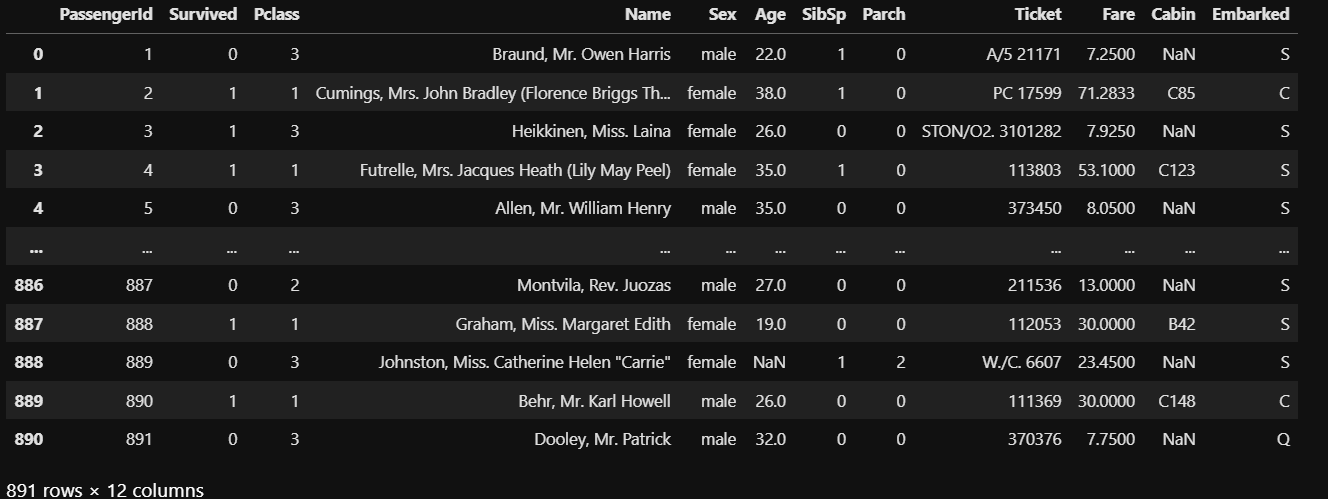
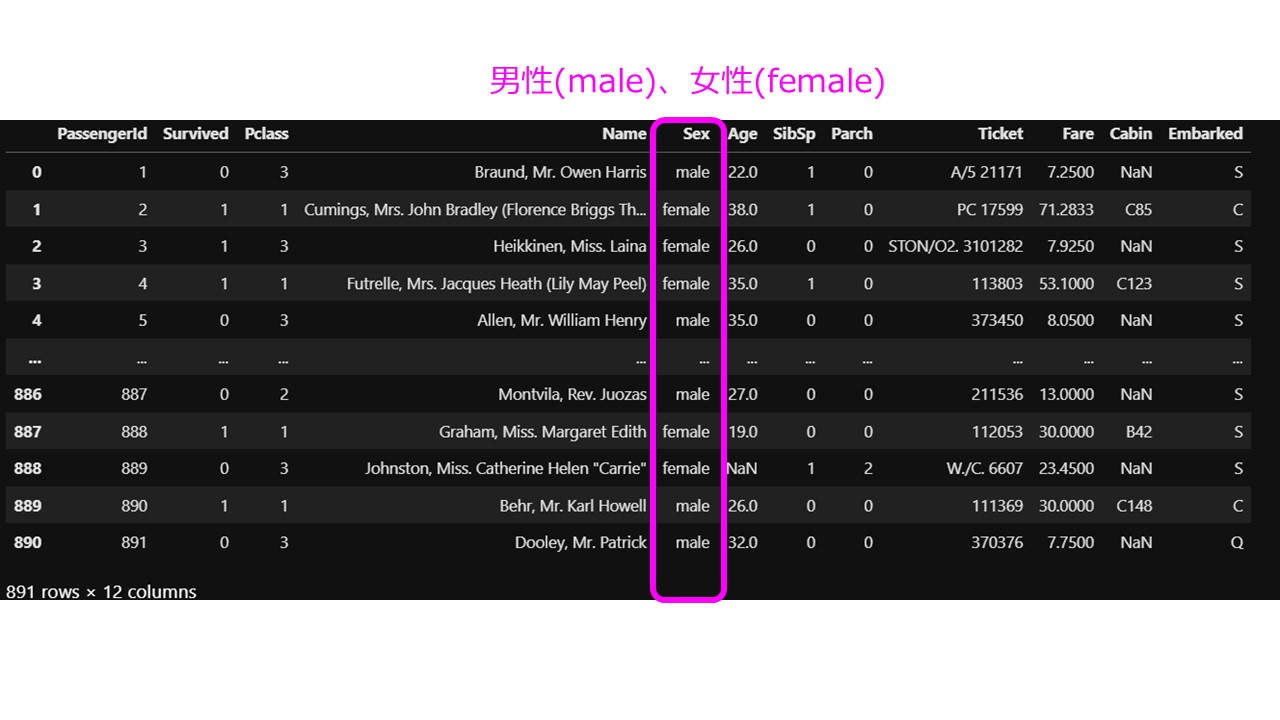
列のそれぞれの意味は以下のような内容となっています。
| PassengerId | 乗客識別ユニークID |
| Survived | 生存フラグ(0=死亡、1=生存) |
| Pclass | 客室等級(チケットクラス) 1stクラス、2ndクラス、3rdクラス |
| Name | 乗客の名前 |
| Sex | 性別(male=男性、female=女性) |
| Age | 年齢 |
| SibSp | タイタニックに同乗している兄弟/配偶者の数 |
| parch | タイタニックに同乗している親/子供の数 |
| ticket | チケット番号 |
| fare | 料金 |
| cabin | 客室番号 |
| Embarked | 出港地(タイタニックへ乗った港) |
| cabin | 客室番号 |
| Embarked | 出港地(タイタニックへ乗った港) |
データの欠損数やデータの型を確認しましょう。
|
1 |
df_taitanic.info() |
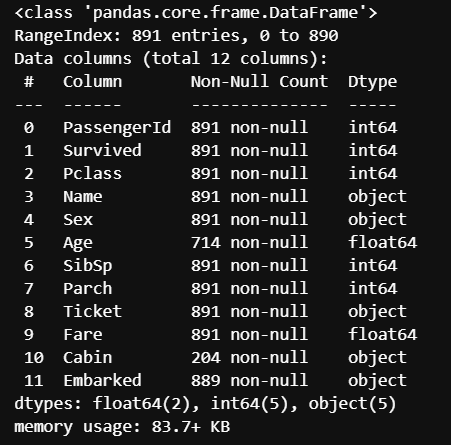
Age(年齢)やcabin(客室番号)に欠損値があるのがわかるでしょう。
SeabornはとてもPandasととても相性の良い優秀なライブラリでデータの可視化を簡単に少ないコードで示すことができます。
タイタニック号の乗客はどのような人達だったのか?
乗客をカテゴリーごとに分析してみましょう。
カテゴリーとしては、以下のものが挙げられます。
- 性別
- 年齢
- 客室等級
まずは男性・女性の人数の確認を行います。
 男性・女性の分類は「Sex」の列に記載されていますので、以下のようにseabornを使って「data」と「カラム(列)」を指定してsns.countplot(‘Sex’, data=df_taitanic)と書くことで数を調べることができます。
男性・女性の分類は「Sex」の列に記載されていますので、以下のようにseabornを使って「data」と「カラム(列)」を指定してsns.countplot(‘Sex’, data=df_taitanic)と書くことで数を調べることができます。
|
1 |
sns.countplot('Sex', data=df_taitanic) |
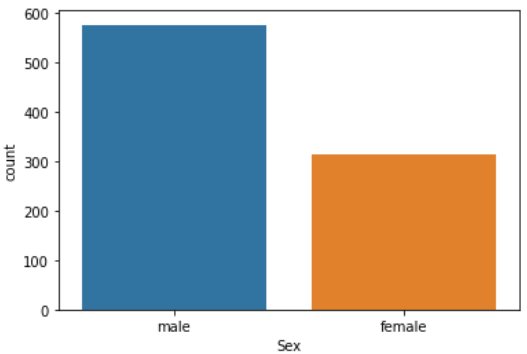
男性の方が乗客数が多かったということがわかりますね。
次に、性別の中で客室等級(1,2,3)による分類も見てみましょう。
|
1 |
sns.countplot('Sex', data=df_taitanic, hue='Pclass') |
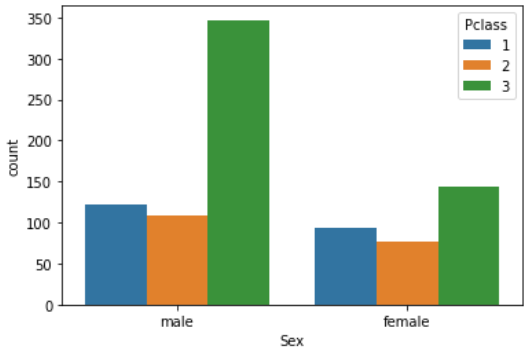
今までは性別に対しての数を調べましたが、今度は「客室等級(Pclass)」に対しての数を見てみましょう。
|
1 |
sns.countplot('Pclass', data=df_taitanic, hue='Sex') |
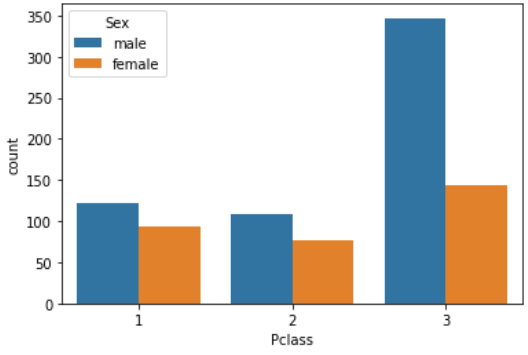
ここまでで、男性の数が女性よりも多く、性別で特に差があるのは「Pclassの3」についてだとわかりました。
客室等級による生存数を確認
客室等級による生存確率を確認します。
まずは死亡者のヒストグラムを可視化してみましょう。
|
1 2 |
sns.distplot(df_taitanic[df_taitanic['Survived'] == 0 ]['Pclass'], norm_hist=True, bins=3) plt.legend(['Survived']) |
【結果】
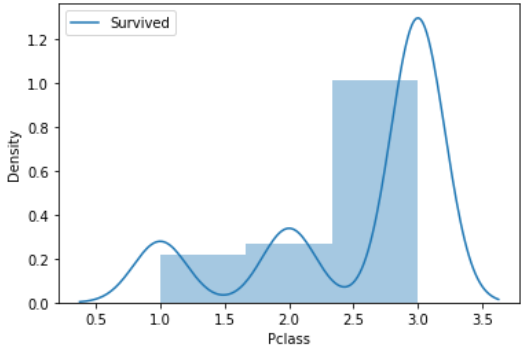
死亡者数は客室等級3の人がかなり多いというのがわかりますね。
次に、生存者の客室等級のヒストグラムを見てみましょう。
|
1 2 |
sns.distplot(df_taitanic[df_taitanic['Survived'] == 1 ]['Pclass'], norm_hist=True, bins=3) plt.legend(['Survived']) |
【結果】

生存者に対しては客室等級1等級の人が生存者が比較的多いことがわかりました。
重ねて書くこともできます。
|
1 2 3 |
sns.distplot(df_taitanic[df_taitanic['Survived'] == 0 ]['Pclass'], norm_hist=True, bins=3) sns.distplot(df_taitanic[df_taitanic['Survived'] == 1 ]['Pclass'], norm_hist=True, bins=3) plt.legend(['Not Survived','Survived']) |
【結果】

客室等級が低いほど死亡者の割合が多くなる傾向にあるのがわかりましたね。
客室等級と年齢の関係を見る
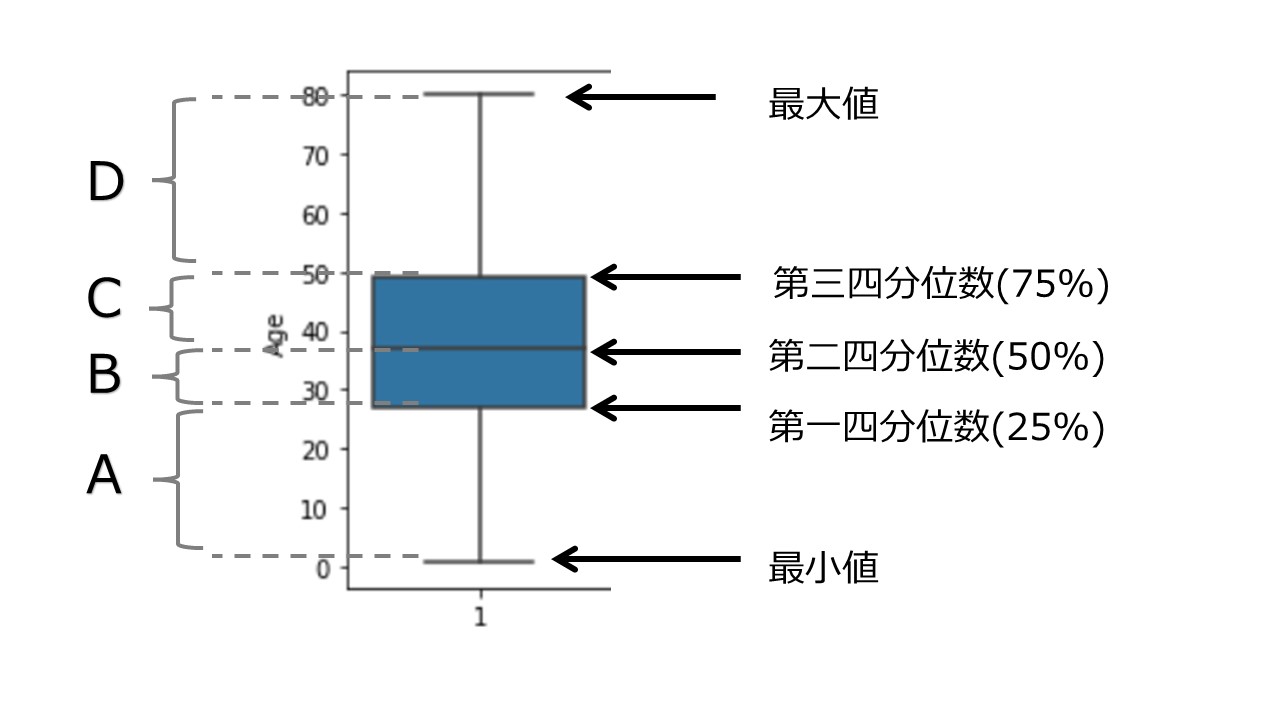
ここでは箱ひげ図というのを紹介します。
箱ひげ図には最大値、最小値と四分位数の情報が含まれています。四分位数はデータを小さい順に並べて、小さいものから順位を付けた時に何パーセント占めるかを示したものです。
- 最小値:データの中で最小の値
- 25%(全体の1/4の部分)=25パーセンタイル
- 50%(全体の2/4=1/2の部分)=50パーセンタイル
- 75%(全体の3/4の部分)=75パーセンタイル
- 最大値:データの中で最大の値
 客室等級に対して年齢層の分布を見てみましょう。
客室等級に対して年齢層の分布を見てみましょう。
|
1 |
sns.boxplot(x=df_taitanic.Pclass,y=df_taitanic.Age,data=df_taitanic) |

客室等級1stクラスになるほど高い年齢層の人が多いということがわかりますね。
大人と子供に分類する
子供やお年寄りの方を優先的に救助すると考えられるため、生存率には大人と子供といったカテゴリー分けが重要であると考えられます。
年齢の平均値を確認しましょう。
|
1 2 |
taitacic_median = df_taitanic['Age'].median() taitacic_median |
【結果】
|
1 |
29.69911764705882 |
全体の年齢平均値は29.6歳であることがわかりました。
次に16歳未満の人は子供として新たなカラム「person」を追加しましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 16歳未満を子供とします。 def male_female_child(passenger): # 年齢と性別のデータを取得します。 age,sex = passenger # 年齢を調べて16歳未満なら、子供。それ以外は性別をそのまま返します。 if age < 16: return 'child' else: return sex # personという新しい列を追加します。 df_taitanic['person'] = df_taitanic[['Age','Sex']].apply(male_female_child,axis=1) |
これにより「person」には「male(男性)、female(女性)、child(子供)」の3つのカテゴリーが作成されました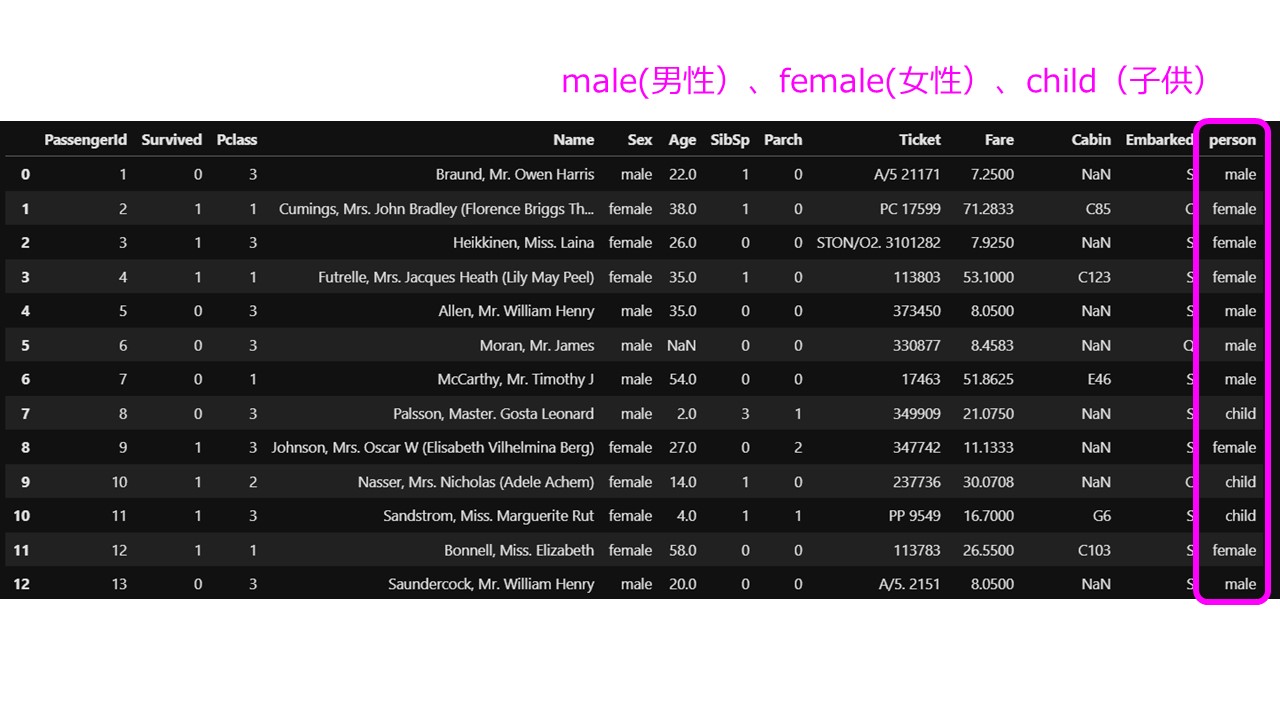 男性、女性、子供の数を確認しましょう。
男性、女性、子供の数を確認しましょう。
|
1 |
df_taitanic['person'].value_counts() |
【結果】
|
1 2 3 4 |
male 537 female 271 child 83 Name: person, dtype: int64 |
性別、大人子供における数を知ることができました。
データの相関係数を見る
項目間の関係性を表す統計量として相関係数があります。
Pandasを使えば相関係数をすぐに調べることができます。
|
1 |
df_taitanic.corr() |
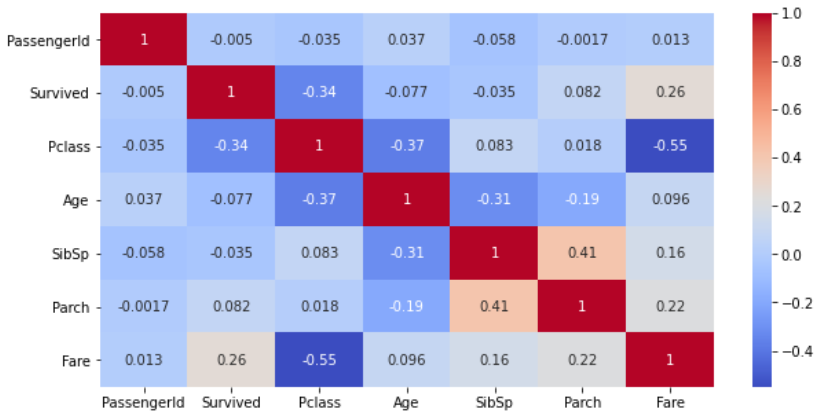
【結果】

知りたいのは「Survived(生存者)」との相関ですね。
どの項目とSurvived(生存者)とが関係がありそうかうかをざっとながめることができます。
ただ、数字だけだと見づらいため視覚的にわかるようにヒートマップを作成してみましょう。
|
1 2 3 |
corr=df_taitanic.corr() plt.figure(figsize=(10,5)) sns.heatmap(corr,annot=True,cmap='coolwarm') |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# FacetGridを使うと、複数のカーネル密度推定のグラフを1つのプロットに描くことができます。 # 性別で層別化して、グラフを少し横長に設定します。 fig = sns.FacetGrid(df_taitanic, hue="person",aspect=4) # mapを使って、性別ごとにkdeplotを描くようにします。 fig.map(sns.kdeplot,'Age',shade= True) # xの最大値を長老に合わせます。 oldest = df_taitanic['Age'].max() # x軸の範囲を設定します。 fig.set(xlim=(0,oldest)) # 凡例を付け加えておきましょう。 fig.add_legend() |
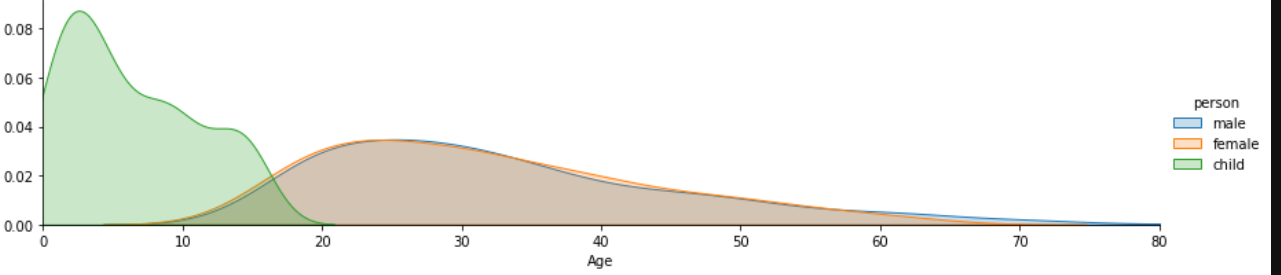
|
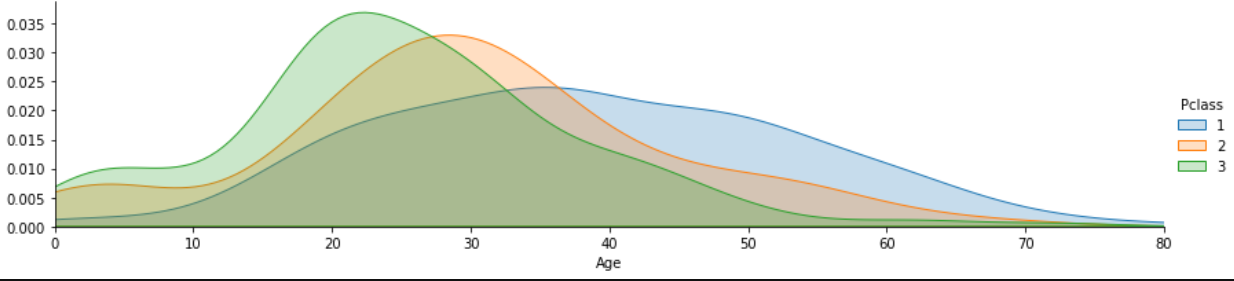
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# FacetGridを使うと、複数のカーネル密度推定のグラフを1つのプロットに描くことができます。 # 性別で層別化して、グラフを少し横長に設定します。 fig = sns.FacetGrid(df_taitanic, hue="Pclass",aspect=4) # mapを使って、性別ごとにkdeplotを描くようにします。 fig.map(sns.kdeplot,'Age',shade= True) # xの最大値を長老に合わせます。 oldest = df_taitanic['Age'].max() # x軸の範囲を設定します。 fig.set(xlim=(0,oldest)) # 凡例を付け加えておきましょう。 fig.add_legend() |
客室番号の人数を確認する
次に、客室番号の人数を確認してみましょう。
客室番号はheaderの「Cabin」の列に当たるデータです。
|
1 |
df_taitanic['Cabin'] |
【結果】
|
1 2 3 4 5 6 7 8 9 10 11 12 |
0 NaN 1 C85 2 NaN 3 C123 4 NaN ... 886 NaN 887 B42 888 NaN 889 C148 890 NaN Name: Cabin, Length: 891, dtype: object |
C85、B42などのように英数字と数字で客室番号が割り振られています。
しかし、どの客室番号の人だったのかを確認するのが難しかったようでデータの欠損値(NaN)が多く存在します。
欠損地を取り除いた方がエラーを防ぐことができるため、欠損値を取り除きます。
|
1 2 |
deck = df_taitanic['Cabin'].dropna() deck |
【結果】
|
1 2 3 4 5 6 7 8 9 10 11 12 |
1 C85 3 C123 6 E46 10 G6 11 C103 ... 871 D35 872 B51 B53 B55 879 C50 887 B42 889 C148 Name: Cabin, Length: 204, dtype: objectで |
NaNを含めると891個あったデータ数が204になりました。
結構、欠損値が多いのですね。
客室番号の数字に対しては細かく分類する必要がないため、ここでは客室番号の英数字だけを抽出して大まかにデータをカテゴリー分けします。
まずは、上で作成したdeckというデータをfor文を使ってはじめの英数字1文字のみを抽出してリストに格納します。
|
1 2 3 4 5 |
levels = [] for level in deck: levels.append(level[0]) levels |
【結果】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
['C', 'C', 'E', 'C', 'C', 'C', 'D', 'A', 'B', 'D', 'C', 'C', 'B', ・・・ ] |
客室番号の英数字1文字だけを抽出しました。
これを新たにDataFrameにします。
|
1 2 3 |
df_cabin = pd.DataFrame(levels) df_cabin.columns = ['Cabin'] df_cabin |
【結果】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Cabin 0 C 1 C 2 E 3 G 4 C ... ... 199 D 200 B 201 C 202 B 203 C 204 rows × 1 columns |
このDataFrameを使って客室番号に対する人数を可視化してみましょう。
以下のようにseabornのcountplotを使って可視化します。
引数を以下のようにします。
sns.countplot(
- ‘Cabin’, :カラム名
- data=df_cabin,:データフレーム
- palette=’winter_d’,:配色
- order=sorted(set(levels)):並び順
)
|
1 |
sns.countplot('Cabin', data=df_cabin, palette='winter_d', order=sorted(set(levels))) |
【結果】
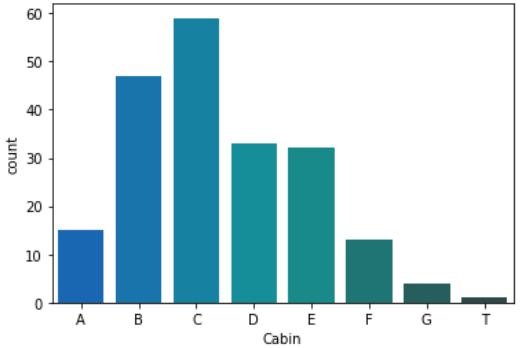
出港地を確認する
もう一度データフレームを確認しておきましょう。
|
1 |
df_taitanic.head() |
【結果】

数の確認はseabornのcountplotを使えば簡単に確認できますね。
出港地はDataFreameの「Embarked」のカラムなので、Embarkedでカテゴリー分けて人数を確認しつつ、Pclassでチケットクラスによる人数を確認してみましょう。
|
1 |
sns.countplot('Embarked', data=df_taitanic, hue='Pclass') |
【結果】

数の確認にはPandasのメソッドを使えば確認ができます。
|
1 |
df_taitanic['Embarked'].value_counts() |
【結果】
|
1 2 3 4 |
S 644 C 168 Q 77 Name: Embarked, dtype: int64 |
ちなみに、数の確認はPythonのライブラリを使っても確認できます。
必要なライブラリをインポートします。
|
1 2 3 4 |
from collections import Counter Counter(df_taitanic.Embarked) |
【結果】
|
1 |
Counter({'S': 644, 'C': 168, 'Q': 77, nan: 2}) |
数の確認だけをしたい場合Pandasのvalue_counts()を使う方が簡単かもしれませんね。
家族連れか独りのどちらが生存率が高いのか?
続いて家族連れか一人の乗客のどちらが生存率が高いかを見てみましょう。
なんとなく子供・女性・お年寄りの生存率が高く、それに伴って家族である男性も救助されるのではないかと予想されます。
同乗者のデータ項目は以下です。
| SibSp | タイタニックに同乗している兄弟/配偶者の数 |
| parch | タイタニックに同乗している親/子供の数 |
なので、その和が家族の人数ということですね。
|
1 2 |
df_taitanic['Alone'] = df_taitanic.SibSp + df_taitanic.Parch df_taitanic.head() |
【結果】

0が独りの乗客、1以上が誰か家族がいる場合ということになります。
では、人数によって生存者数がどうなっているのかを確認してみましょう。
|
1 |
sns.countplot('Alone', data=df_taitanic, hue='Survived', palette='summer_r') |
【結果】
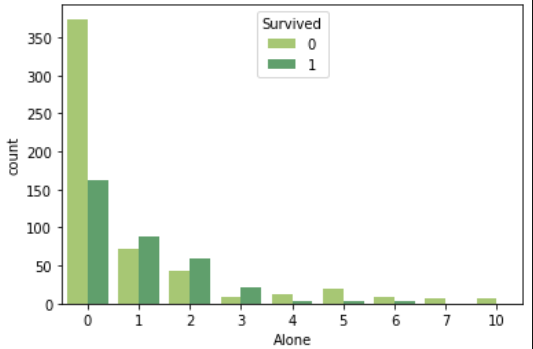
見ると家族連れの人の方が死亡者数より生存者数が多い傾向にあります。
知りたいのは何人家族がいて、そのときどれくらいの割合で生存していたかということですね。
生存率=生存者数/人数を計算することになります。
今、Survivedの「0:死亡、1:生存」なので平均値を計算することで生存率を計算することができます。

「Alone」のカラムでカテゴリー分けして、平均値をとりましょう。
|
1 2 |
df_taitanic_mean = df_taitanic.groupby('Alone',as_index=False).mean() df_taitanic_mean |
【結果】
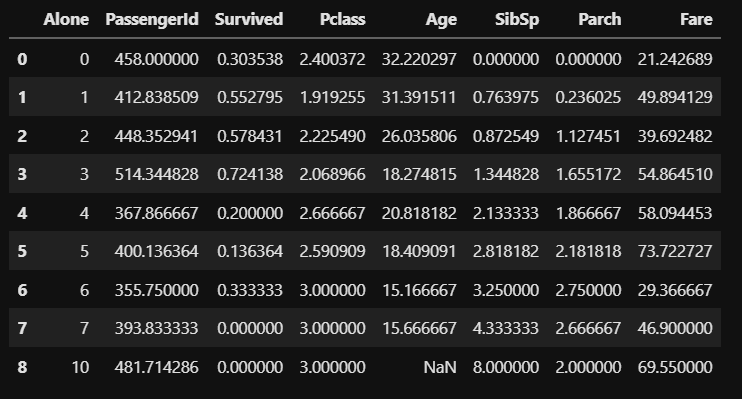
引数に「as_index=False」としないと、カテゴリー分けする「Alone」がデータではなくindexになってしまうため、引数をお忘れなく。
パーセント表示にしたいので
|
1 2 |
df_taitanic_mean['Survived'] = df_taitanic.groupby('Alone',as_index=False).mean()['Survived']*100 df_taitanic_mean |
【結果】
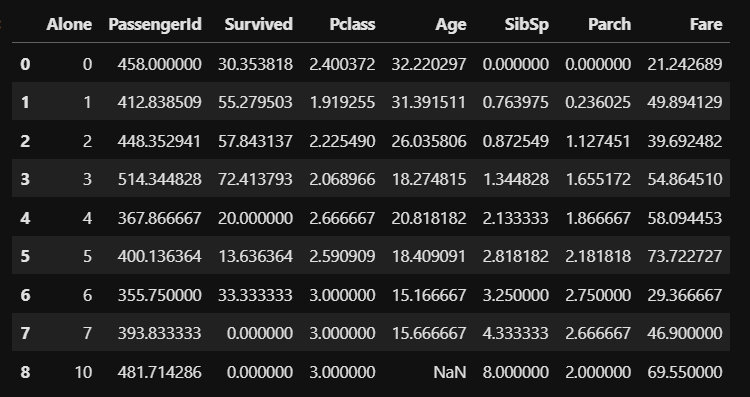
今回使うデータは「Survived」だけです。
|
1 2 |
sns.barplot(x='Alone',y='Survived', data=df_taitanic_mean) plt.ylabel('Survived(%)') |
【結果】
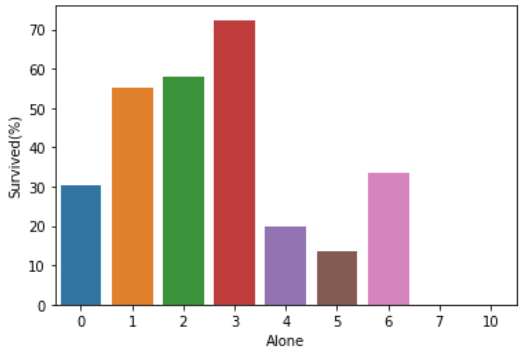
こちらのサイトを参考にラベルをつけることができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
import matplotlib import matplotlib.pyplot as plt import numpy as np labels = df_taitanic_mean['Alone'] men_means = df_taitanic_mean['Survived'].round(1) x = np.arange(len(labels)) # the label locations y = np.arange(0,101,10) # the label locations width = 0.8 # the width of the bars fig, ax = plt.subplots() rects1 = ax.bar(x - width/2, men_means, width, label='Alone') # Add some text for labels, title and custom x-axis tick labels, etc. ax.set_ylabel('Survived(%)') ax.set_title('Survived(%)') ax.set_xticks(x) ax.set_yticks(y) ax.set_xticklabels(labels) ax.legend() def autolabel(rects): """Attach a text label above each bar in *rects*, displaying its height.""" for rect in rects: height = rect.get_height() ax.annotate('{}'.format(height), xy=(rect.get_x() + rect.get_width() / 2, height), xytext=(0, 3), # 3 points vertical offset textcoords="offset points", ha='center', va='bottom') autolabel(rects1) fig.tight_layout() plt.show() |
【結果】
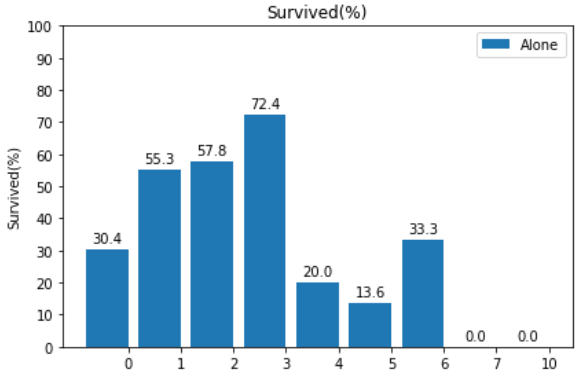
棒グラフのラベルを付けるためのコーディングが手間ですが、ラベルが付いた方が理解がしやすいですね。
結果は家族連れが3人の人の生存率が高く(72.4%)、ひとりでいた方の生存率は家族連れの方よりも低くなっています。
これは、恐らく子供や女性(奥さん)の救助を優先し、そのついでに男性(夫)も救助されたのではないかと思われます。
次に、ざっくりひとり(Alone)だったのか、家族連れ(with Family)だったのかでカテゴリー分けしてみましょう。
|
1 2 |
df_taitanic['Alone'].loc[df_taitanic['Alone'] > 0] = 'with Family' df_taitanic['Alone'].loc[df_taitanic['Alone'] == 0] = 'Alone' |
結果を表示します。
|
1 |
df_taitanic.head(30) |
【結果】
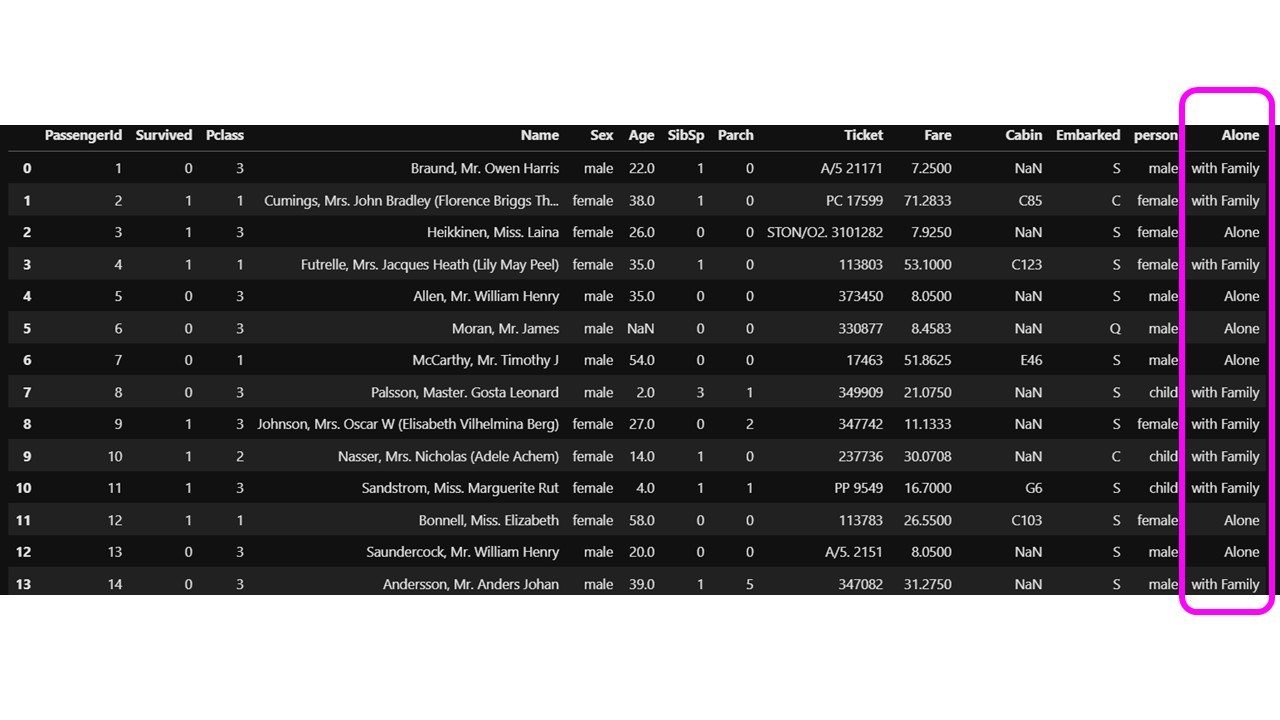 Aloneの列が「Aloneかwith Family」になっていますね。
Aloneの列が「Aloneかwith Family」になっていますね。
列のカテゴリーの種類は以下のようにuniqueメソッドで確認ができます。
|
1 |
pd.unique(df_taitanic['Alone']) |
【結果】
|
1 |
array(['with Family', 'Alone'], dtype=object) |
では、ひとりか家族連れ化で生存者数に違いがあるのかを確認してみましょう。
|
1 |
sns.countplot('Alone', data=df_taitanic, hue='Survived', palette='Greens') |
【結果】
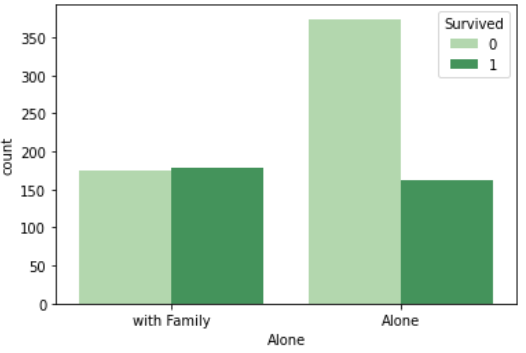
なんと結果はやはり家族連れの方が生存者数が割合が多そうですね。
具体的な割合はAloneでカテゴリー分けして平均をとることで調べることができます。
|
1 |
df_taitanic.groupby('Alone').mean() |
【結果】
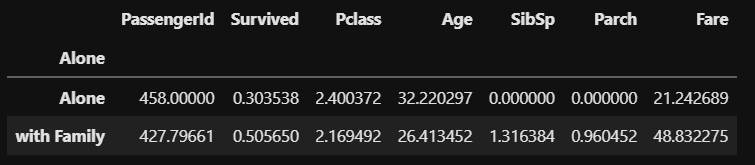
確認すると「Survived」の列が以下のようになっています。
- Alone:0.303538(約30%)
- with Family:0.505650(約50%)
これは人数に対する生存者数の割合(生存率)です。
やはり家族連れの方が生存率が高いということが言えそうです。
男女と年齢別で生存者を確認する
さきほどの考察では子供や女性を先に救助され、それが家族連れの方が生存率が高いという結果になったと考えました。
ここでは、具体的に男女と年齢による生存者の分布を確認してみましょう。
|
1 2 |
#ラベルごとに分けて表示 sns.catplot(x='Sex', y='Age', data=df_taitanic, kind='swarm', hue='Survived') |
【結果】
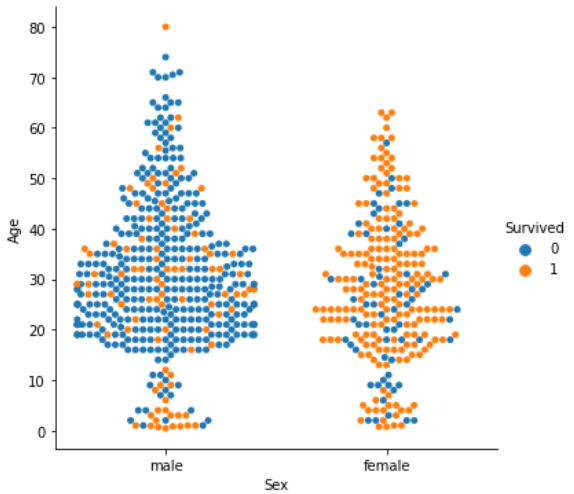
形状が蜂の巣に似ていることから、”beeswarm(蜜蜂)と呼ばれており、各データポイントが重ならないようにplotするものです。男女で比較すると女性の方が生存者が多く、男性でも10代の人は比較的生存者が多いという結果となりました。
チケットクラスと年齢で生存者を確認
チケットクラスも生存率に多くかかわっているということなので、チケットクラスと年齢別でbeeswarm(蜜蜂)を確認しましょう。
|
1 2 |
#ラベルごとに分けて表示 sns.catplot(x='Pclass', y='Age', data=df_taitanic, kind='swarm', hue='Survived') |
【結果】
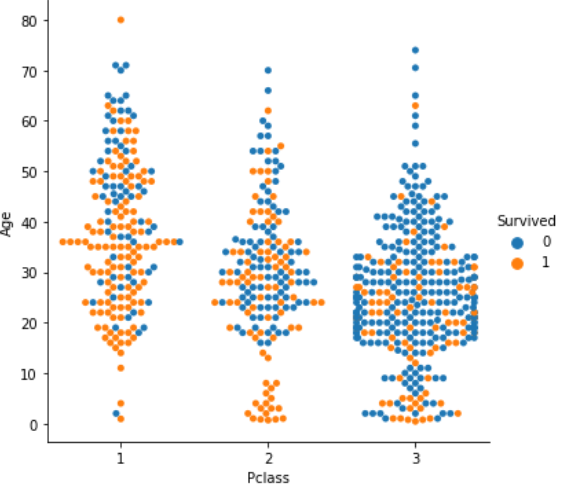
やはりチケットクラスが1等客室の人の生存者数が多いですね。
その他にもvioletと呼ばれるバイオリンの形になる分布の表示もできます。
|
1 |
sns.catplot(x = 'Pclass', y = 'Age',hue = 'Survived',data = df_taitanic, kind = 'violin') |
【結果】
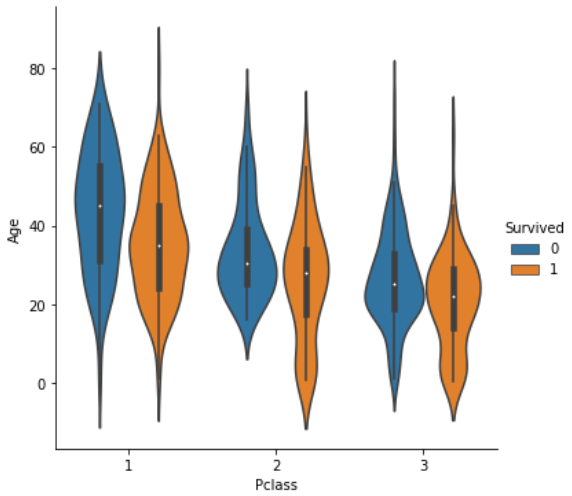
別の見方としてポイントを線で結んだ表現もできます。
|
1 |
sns.catplot('Pclass', 'Survived', data=df_taitanic, kind="point") |
【結果】
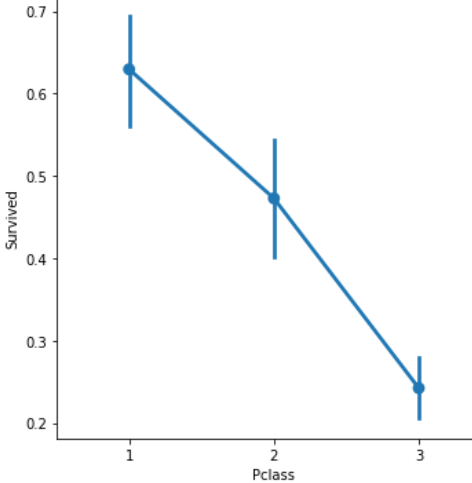
3等客室の乗客の生存率はかなり低いことが分かります。ただし、これは3等客室に男性が多い、つまり、「女性と子供を先に」というポリシーの犠牲になったのかもしれません。これを調べるために、もう少し詳しく見ていきましょう。
|
1 2 3 |
# 性別を考慮して、factorplotを描きます。 sns.catplot('Pclass', 'Survived', hue='person', data=df_taitanic, order=[1,2,3], kind='point', aspect=2) |
【結果】
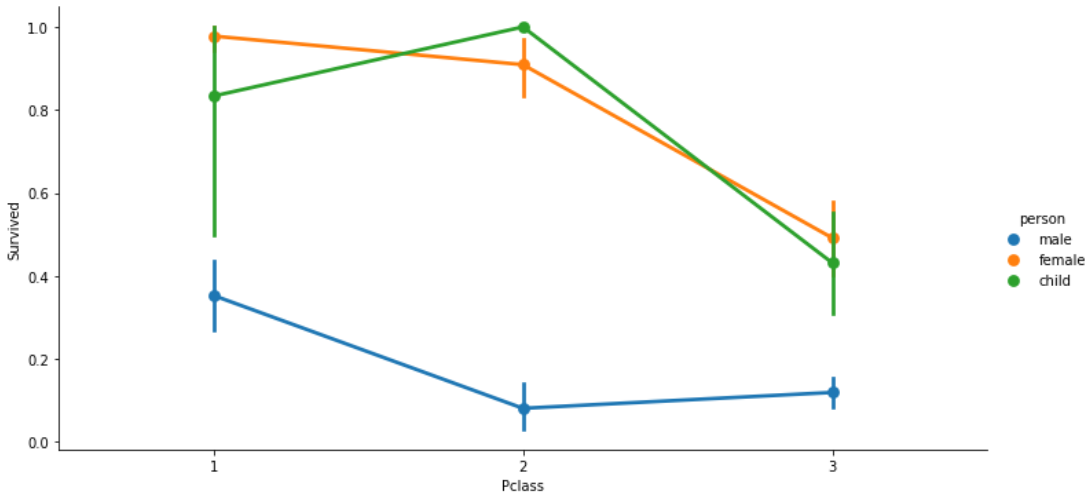
チケットクラスが1等客室、男性よりも女性や子供の方が生存率が高いことがわかります。
ここまで、以下の変数が生存率に影響してる可能性が高いことがわかりました。
では、子供でかつ客室1等級の生存率を確認しましょう。
|
1 |
df_taitanic[(df_taitanic['person']=='child') & (df_taitanic['Pclass']==1)].mean() |
【結果】
|
1 2 3 4 5 6 7 8 9 |
PassengerId 4.965000e+02 Survived 8.333333e-01 Pclass 1.000000e+00 Age 7.820000e+00 SibSp 6.666667e-01 Parch 1.833333e+00 Ticket 1.896352e+32 Fare 1.393826e+02 dtype: float64 |
Survivedを確認すると8.333333e-01(約83%)の生存率という結果です。
では、女性でかつ客室1等級の生存率を確認しましょう。
|
1 |
df_taitanic[(df_taitanic['person']=='female') & (df_taitanic['Pclass']==1)].mean() |
【結果】
|
1 2 3 4 5 6 7 8 |
PassengerId 469.032967 Survived 0.978022 Pclass 1.000000 Age 35.500000 SibSp 0.549451 Parch 0.417582 Fare 104.317995 dtype: float64 |
こちらに至っては0.978022(約98%)の生存率となっています。
一方男性はどうかというと・・・・
|
1 |
df_taitanic[(df_taitanic['person']=='male') & (df_taitanic['Pclass']==1)].mean() |
【結果】
|
1 2 3 4 5 6 7 8 |
PassengerId 454.151261 Survived 0.352941 Pclass 1.000000 Age 42.382653 SibSp 0.302521 Parch 0.235294 Fare 65.951086 dtype: float64 |
0.352941(約36%)の生存率という悲しい結果でした(‘;’)
男性は客室等級に依らず生存率が低いのですね。
回帰曲線を使って性別、年齢、客室の等級の生存率を確認
今までで何が生存率に影響しているのかがわかってきました。
しかし、一発で理解ができる可視化のグラフがあると良いですよね。
何で結果を表現するかはその人のセンスにも依りますが、seabornは非常に優秀な可視化のライブラリが用意されています。
以下のように回帰モデルの可視化を使ってみましょう。
|
1 2 3 4 |
generations = [10,20,30,40,50,60,70,80,90] sns.lmplot(x='Age', y='Survived', data=df_taitanic, hue='Pclass', palette='winter', hue_order=[1,2,3], x_bins=generations) |
【結果】
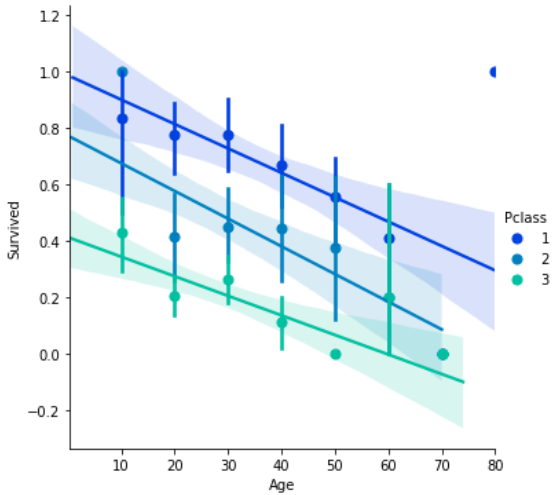
これには性別による影響も含まれているので、性別でわけてグラフを表示してみましょう。
|
1 2 3 |
sns.lmplot(x='Age', y='Survived', data=df_taitanic, hue='Pclass', col='Sex', palette='winter', hue_order=[1,2,3]) |
【結果】
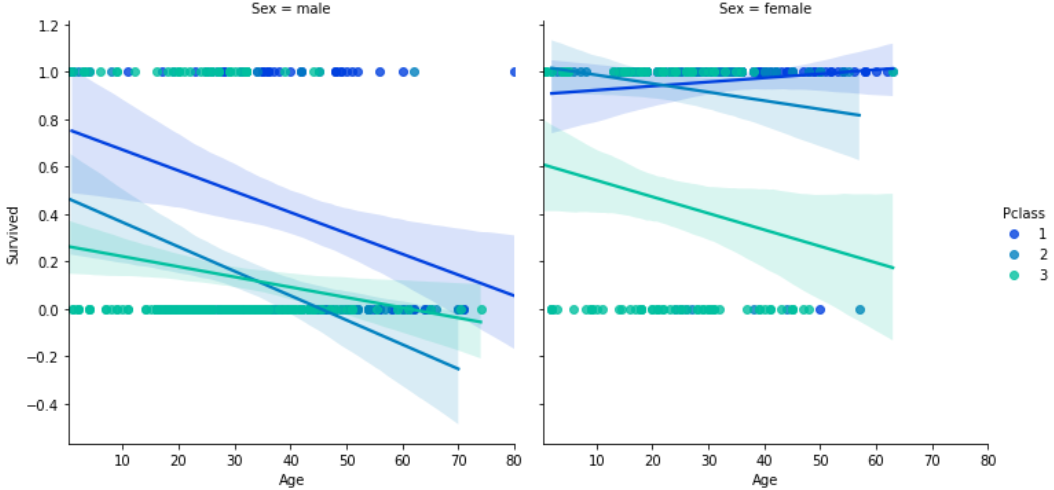
女性でも客室等級1,2が年齢に依らず生存率が高く、客室等級3等級でも年齢が低い方が生存率が高いことがわかります。
|
1 |
sns.countplot('Alone', data=df_taitanic[df_taitanic['person']=='child']) |
【結果】
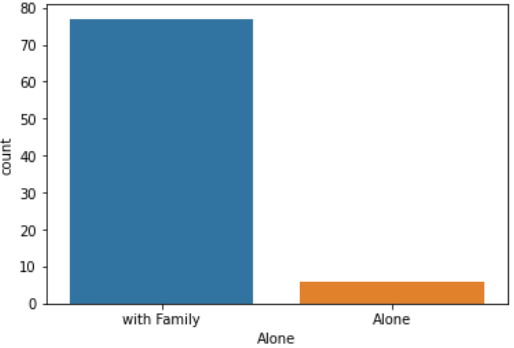
|
1 |
sns.countplot('Alone', data=df_taitanic[df_taitanic['person']=='female']) |
【結果】
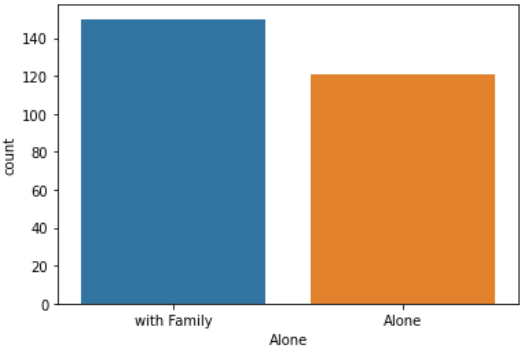
|
1 |
sns.countplot('Alone', data=df_taitanic[df_taitanic['person']=='male']) |
【結果】

|
1 2 3 4 |
sns.lmplot(x='Age', y='Survived', data=df_taitanic, col='Alone', hue='person', palette='plasma', aspect=1, x_bins=generations, fit_reg=True,) plt.ylim([0,1]) |
【結果】
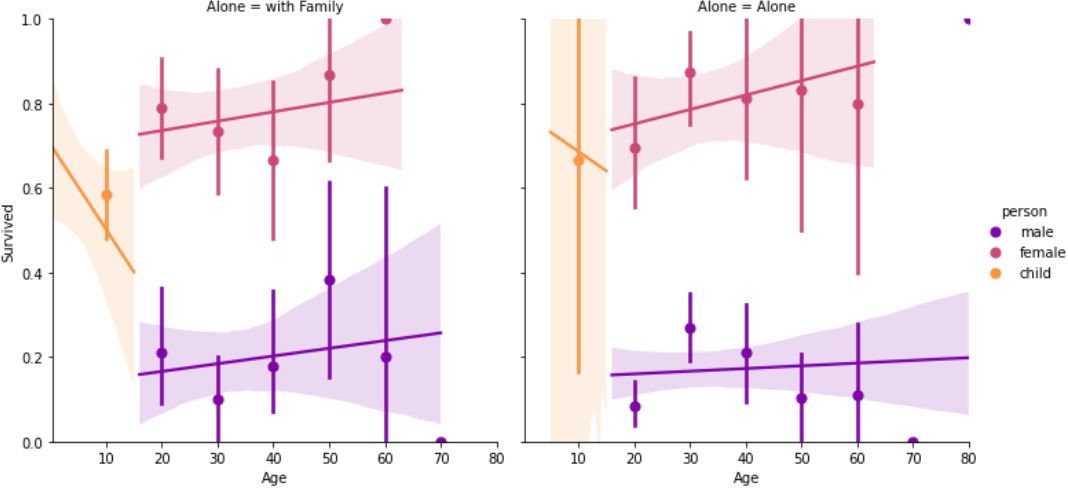
客室等級もごちゃまぜにして行うとこのようになります。
|
1 2 3 4 |
sns.lmplot(x='Age', y='Survived', data=df_taitanic[df_taitanic['Pclass']==1], col='Alone', hue='person', palette='plasma', aspect=1, x_bins=generations, fit_reg=True,) plt.ylim([0,1]) |
【結果】

|
1 2 3 4 |
sns.lmplot(x='Age', y='Survived', data=df_taitanic[df_taitanic['Pclass']==2], col='Alone', hue='person', palette='plasma', aspect=1, x_bins=generations, fit_reg=True,) plt.ylim([0,1]) |
【結果】
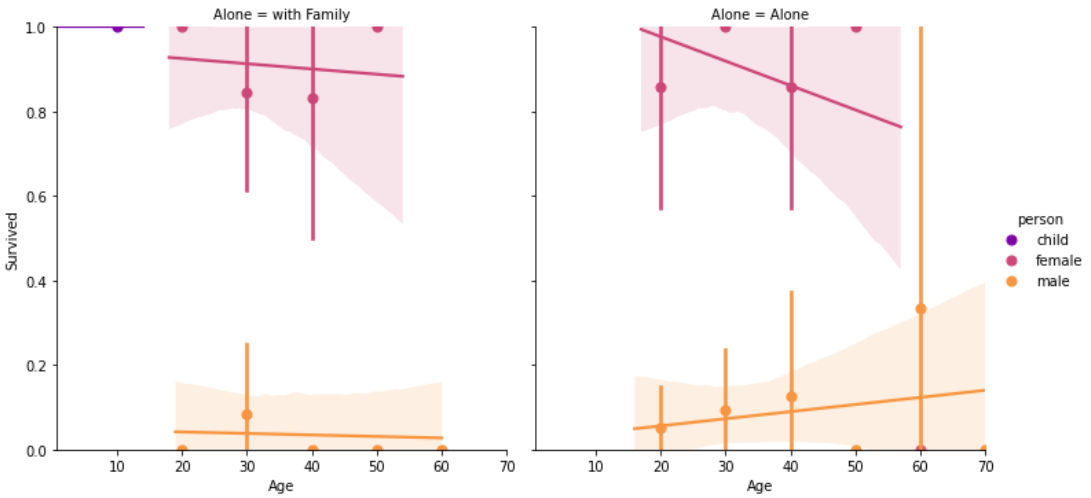
|
1 2 3 4 |
sns.lmplot(x='Age', y='Survived', data=df_taitanic[df_taitanic['Pclass']==3], col='Alone', hue='person', palette='plasma', aspect=1, x_bins=generations, fit_reg=True,) plt.ylim([0,1]) |
【結果】
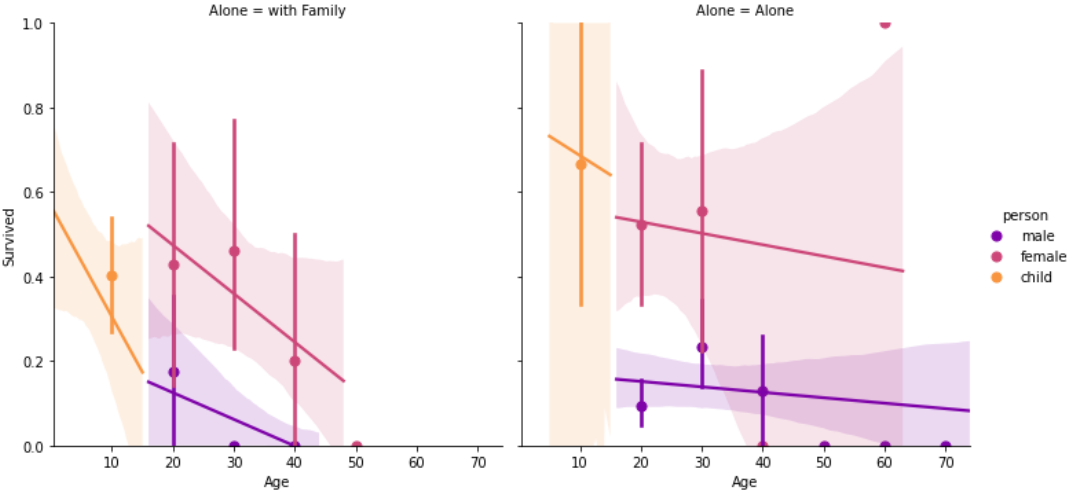
まとめ
今回はkaggleの練習用データであるタイタニック号のデータを使ってデータ分析を行いました。
項目から「性別、年齢、客室等級」が生存率に大きく影響しているということがわかりましたね。